cloudflare workers 解决docker无法拉取镜像问题
由于某些原因,目前国内无法正常拉取docker镜像,去年写的加速拉取镜像的办法也没法用,困难总比办法多(不是),干脆新写一篇教程,利用cloudflare workers 解决docker无法拉取镜像问题。
本篇利用cloudflare workers来解决无法拉取镜像问题,关于cloudflare这里不再过多介绍,cloudflare workers服务也是免费,不懂的童鞋可以自行翻看往期文章《cloudflare加快github下载》。如果看完本篇也不想动手,也可以在后台回复“jsdc”获取我搭建好的公共服务地址。
前排准备:
1.一个域名,不想花钱购买域名可以用免费的二级域名,我之前也有写过相关文章《免费申请注册eu.org二级域名》。
2.cloudflare(以下简称cf)账号。
一、添加域名ns服务器
cf入门以及添加ns解析相关内容请看《利用cloudflare让ipv4与ipv6互通》,这里不再赘述。
二、部署服务
登录cf后,进入Workers 和 Pages,再点击概述,创建应用程序。
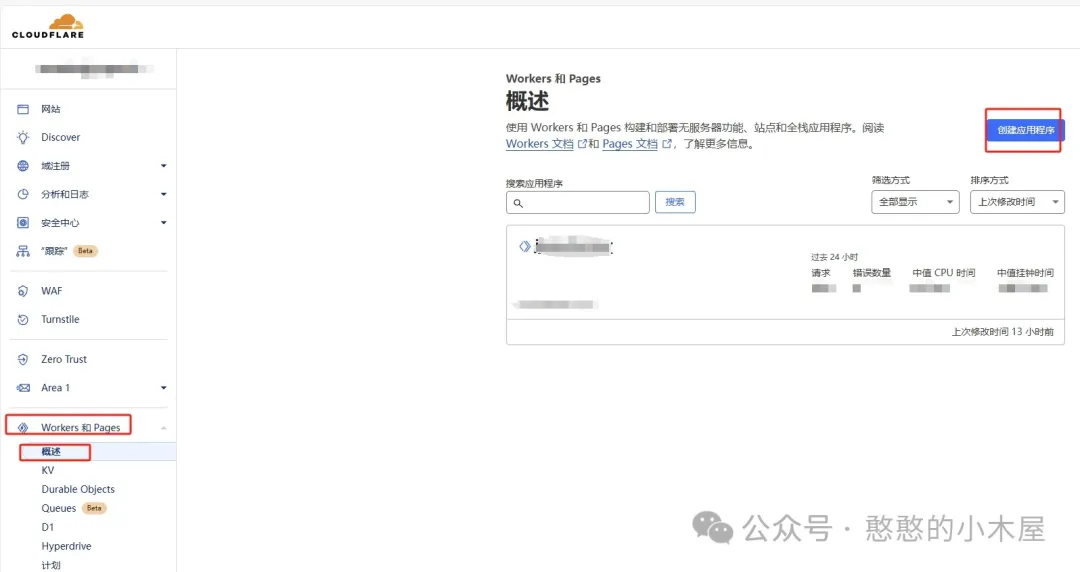
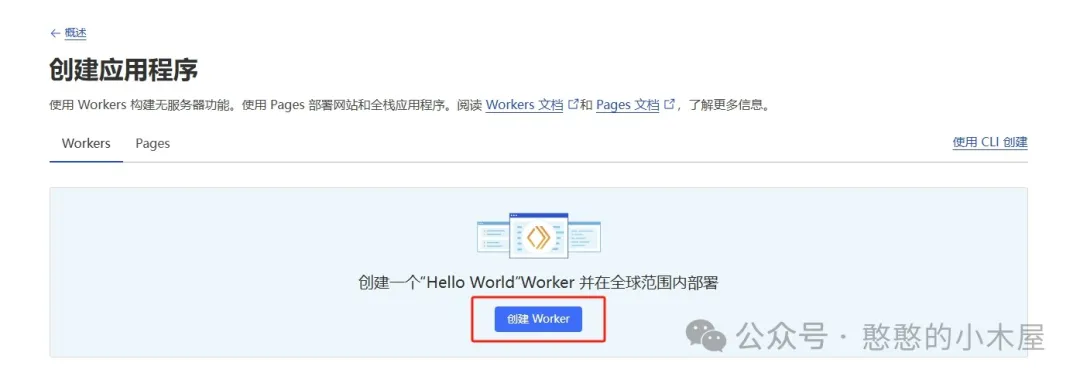
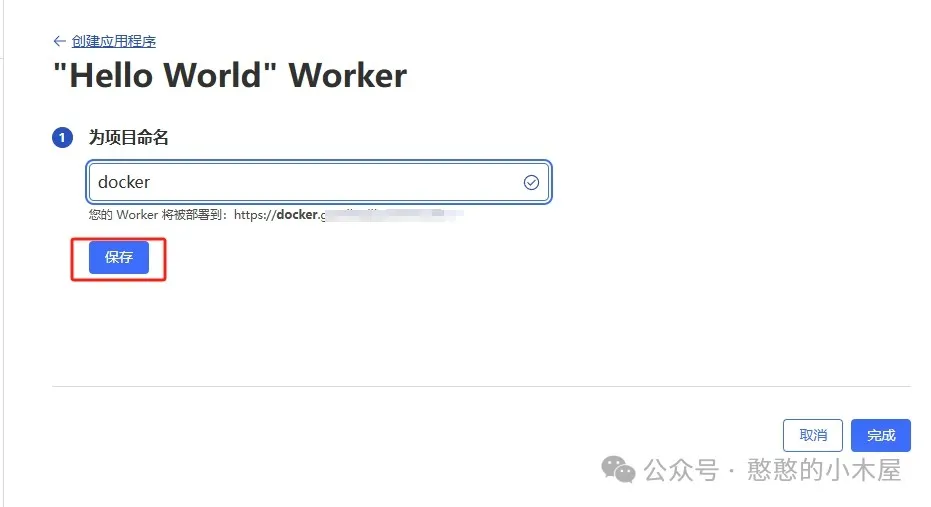
之后再点击创建worker,输入项目名称,然后在下面会有一行小字:您的 Worker 将被部署到:xxxxx,这个是cf自动分配给你的域名,通过这个就可以访问这个项目,有童鞋就会想那为啥还要自己准备域名,因为很简单,cf分配的那个域名目前打不开,只能绑定自己的域名。输入完名称后点击保存,会出现默认的worker.js,这个不用管,点击完成就行
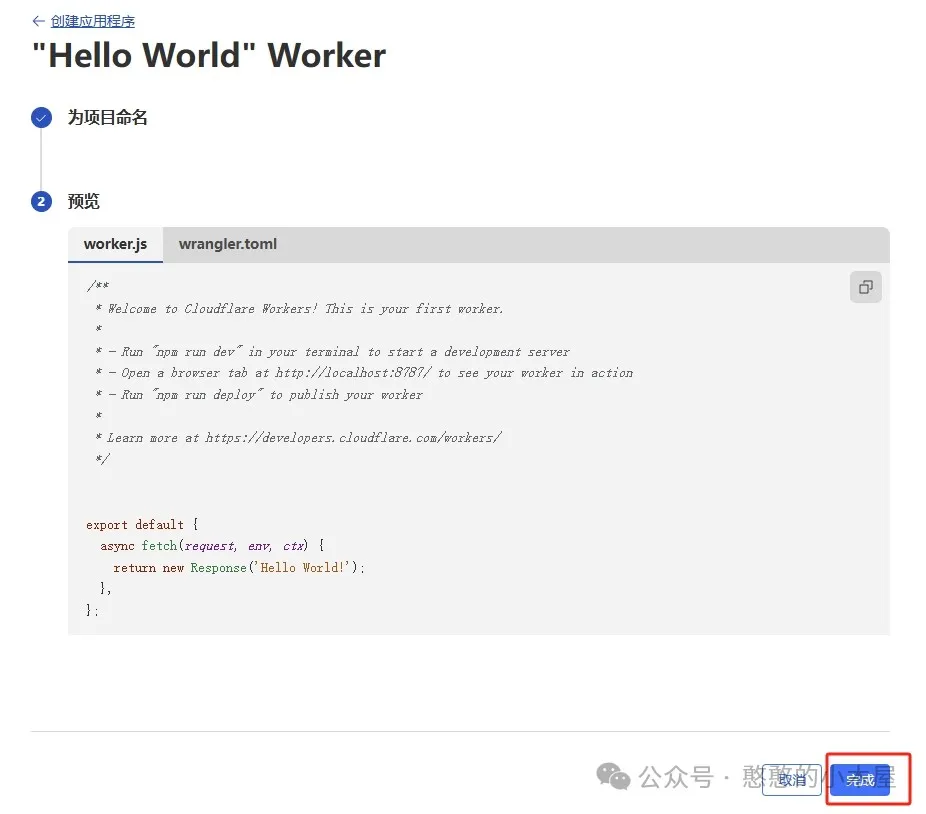
完成后会出现初始界面,点击编辑代码。先删掉默认的代码。
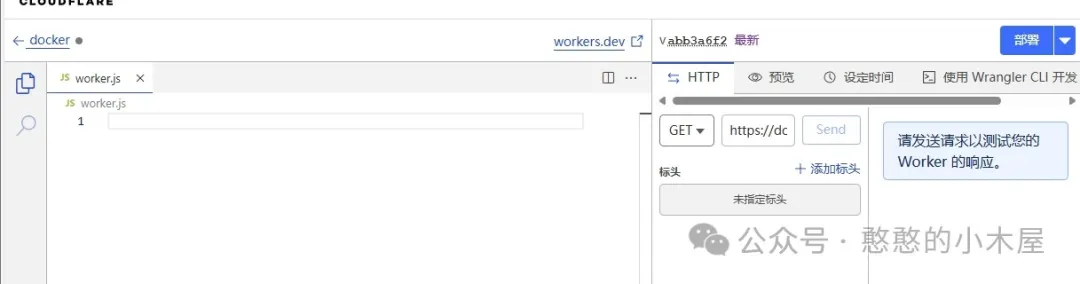
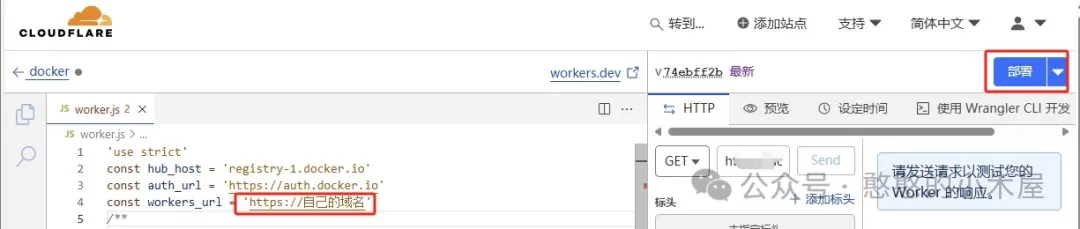
然后把以下代码复制到里面,并替换workers_url为自己的域名,再点击部署。
'use strict'
const hub_host = 'registry-1.docker.io'
const auth_url = 'https://auth.docker.io'
const workers_url = 'https://自己的域名'
const PREFLIGHT_INIT = {
status: 204,
headers: new Headers({
'access-control-allow-origin': '*',
'access-control-allow-methods': 'GET,POST,PUT,PATCH,TRACE,DELETE,HEAD,OPTIONS',
'access-control-max-age': '1728000',
}),
}
function makeRes(body, status = 200, headers = {}) {
headers['access-control-allow-origin'] = '*'
return new Response(body, {status, headers})
}
function newUrl(urlStr) {
try {
return new URL(urlStr)
} catch (err) {
return null
}
}
addEventListener('fetch', e => {
const ret = fetchHandler(e)
.catch(err => makeRes('cfworker error:\n' + err.stack, 502))
e.respondWith(ret)
})
async function fetchHandler(e) {
const getReqHeader = (key) => e.request.headers.get(key);
let url = new URL(e.request.url);
if (url.pathname === '/token') {
let token_parameter = {
headers: {
'Host': 'auth.docker.io',
'User-Agent': getReqHeader("User-Agent"),
'Accept': getReqHeader("Accept"),
'Accept-Language': getReqHeader("Accept-Language"),
'Accept-Encoding': getReqHeader("Accept-Encoding"),
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0'
}
};
let token_url = auth_url + url.pathname + url.search
return fetch(new Request(token_url, e.request), token_parameter)
}
url.hostname = hub_host;
let parameter = {
headers: {
'Host': hub_host,
'User-Agent': getReqHeader("User-Agent"),
'Accept': getReqHeader("Accept"),
'Accept-Language': getReqHeader("Accept-Language"),
'Accept-Encoding': getReqHeader("Accept-Encoding"),
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0'
},
cacheTtl: 3600
};
if (e.request.headers.has("Authorization")) {
parameter.headers.Authorization = getReqHeader("Authorization");
}
let original_response = await fetch(new Request(url, e.request), parameter)
let original_response_clone = original_response.clone();
let original_text = original_response_clone.body;
let response_headers = original_response.headers;
let new_response_headers = new Headers(response_headers);
let status = original_response.status;
if (new_response_headers.get("Www-Authenticate")) {
let auth = new_response_headers.get("Www-Authenticate");
let re = new RegExp(auth_url, 'g');
new_response_headers.set("Www-Authenticate", response_headers.get("Www-Authenticate").replace(re, workers_url));
}
if (new_response_headers.get("Location")) {
return httpHandler(e.request, new_response_headers.get("Location"))
}
let response = new Response(original_text, {
status,
headers: new_response_headers
})
return response;
}
function httpHandler(req, pathname) {
const reqHdrRaw = req.headers
// preflight
if (req.method === 'OPTIONS' &&
reqHdrRaw.has('access-control-request-headers')
) {
return new Response(null, PREFLIGHT_INIT)
}
let rawLen = ''
const reqHdrNew = new Headers(reqHdrRaw)
const refer = reqHdrNew.get('referer')
let urlStr = pathname
const urlObj = newUrl(urlStr)
/** @type {RequestInit} */
const reqInit = {
method: req.method,
headers: reqHdrNew,
redirect: 'follow',
body: req.body
}
return proxy(urlObj, reqInit, rawLen, 0)
}
async function proxy(urlObj, reqInit, rawLen) {
const res = await fetch(urlObj.href, reqInit)
const resHdrOld = res.headers
const resHdrNew = new Headers(resHdrOld)
// verify
if (rawLen) {
const newLen = resHdrOld.get('content-length') || ''
const badLen = (rawLen !== newLen)
if (badLen) {
return makeRes(res.body, 400, {
'--error': `bad len: ${newLen}, except: ${rawLen}`,
'access-control-expose-headers': '--error',
})
}
}
const status = res.status
resHdrNew.set('access-control-expose-headers', '*')
resHdrNew.set('access-control-allow-origin', '*')
resHdrNew.set('Cache-Control', 'max-age=1500')
resHdrNew.delete('content-security-policy')
resHdrNew.delete('content-security-policy-report-only')
resHdrNew.delete('clear-site-data')
return new Response(res.body, {
status,
headers: resHdrNew
})
}
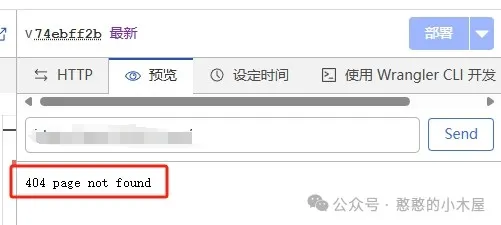
这个代码里面不包含web界面,所以直接访问会提示404,这个是正常的,不带web界面是因为添加web界面要改动几个地方,而且web界面也没用,不如从简,能保证正常拉取镜像就行。
三、绑定域名并配置路由
cf workers默认使用的是自动分配的域名,目前是不可访问,所以还需要绑定自己的域名。
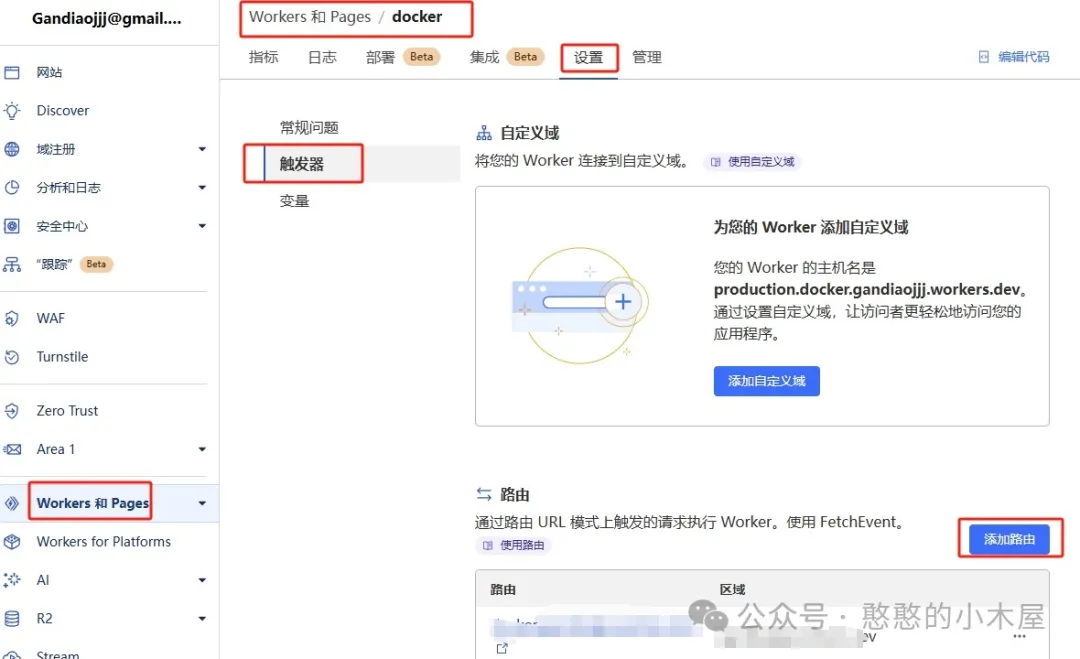
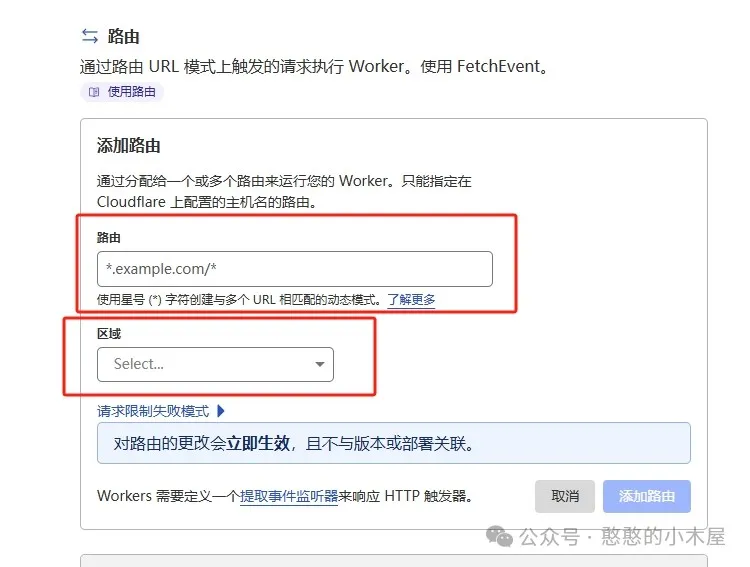
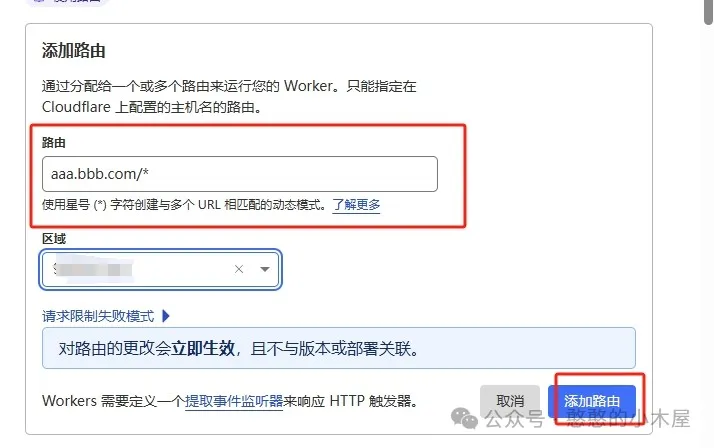
进入项目详细-设置里面,选择触发器,点击添加路由。路由就填写对应的子(主)域名,例如主域名是“bbb.com”,想要通过“aaa.bbb.com”拉取docker,那路由就填写“aaa.bbb.com/*”,当然这里想直接用主域名也可以,没限制;区域就选择对应的主域名,然后添加路由。
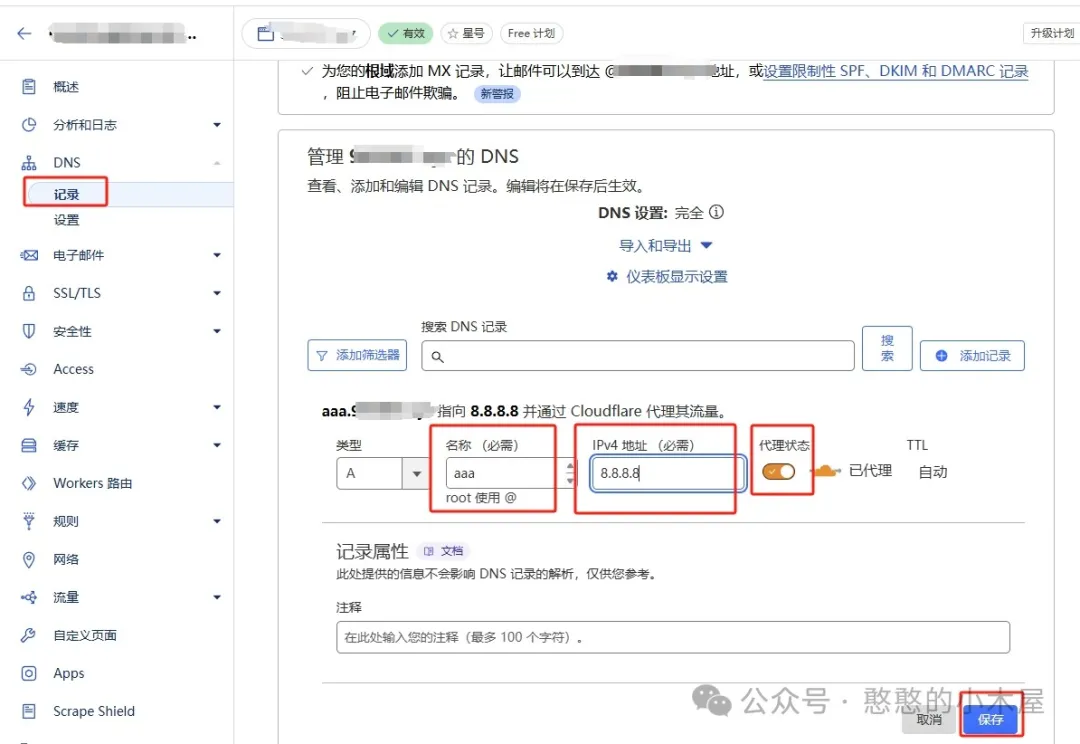
之后进入dns解析,添加一个对应子(主)域名的解析,例如上面是用“aaa.bbb.com”,那这里就添加一个对应的ipv4解析记录;解析地址随便填写,填8.8.8.8就可以,然后旁边的小云朵一定要启用。
四、验证并拉取镜像
如果以上步骤都无误,就可以直接拉取docker镜像,但是需要对相应的拉取命令做更改。
1.常规拉取镜像
例如原拉取命令如下:
docker pull library/alpine:latest
那就需要在前面加上自己的域名:
docker pull 自己的域名/library/alpine:latest
当然也可以直接设置docker registry,替换成自己的域名即可:
sudo tee /etc/docker/daemon.json <<EOF
{
"registry-mirrors": ["https://自己的域名"]
}
EOF
2.nas拉取镜像
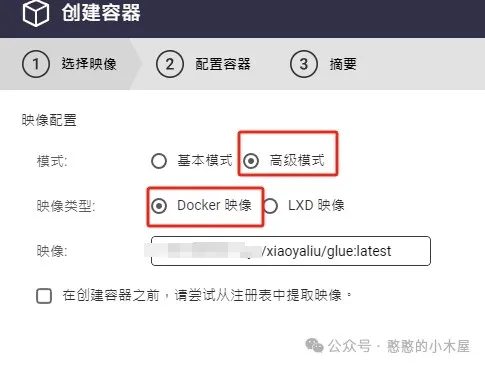
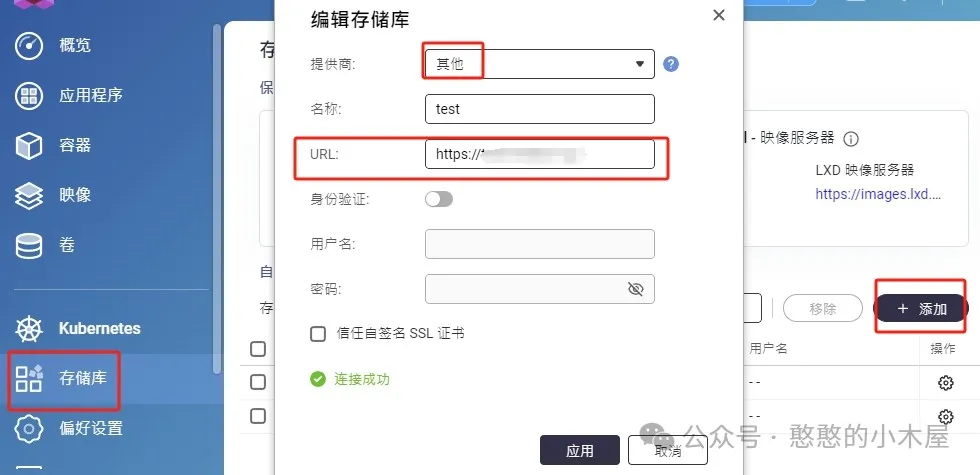
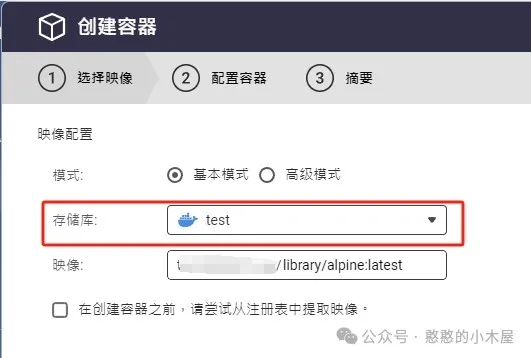
如果是用的nas,以威联通为例,可以直接在添加docker时候选择高级模式,输入自己的域名来拉取docker;也可以在存储库中添加对应的registry,注意供应商要选择其他,url要填写完整(带https),之后在创建容器的时候选择对应的存储库就行。
3.其他
其他系统或者设备参照上面的方法修改对应的源(registry)就行。
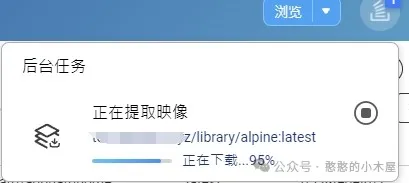
如果配置无误,就可以正常下载镜像了。
六、其他
1.cf workers每日总计免费10w次请求额度,普通人是几乎不可能用完,但为防止滥用仍建议添加路由和规则限制他人使用。
2.这个本质上是利用cf来进行流量中转,受限于cf的速度,如果自己所在地区cf不可用或者速度偏低,那可以自己用服务器搭建对应的中转服务,相关内容以后再出一期。
3.在后台回复“jsdc”即可获取我已经搭建好的服务,但本人不保证可用性,如果被滥用会直接关闭。