Why HermesAgent Would Not Reply in WeChat or WeCom: The Real Culprit Was a Local Relay With a 3-Second Timeout
The short version
This incident looked like a model problem or a broken messaging channel, but the real failure happened one layer lower: my local relay cut the upstream request off after 3 seconds. That was fine for quick health checks, but it was wrong for real WeChat and WeCom turns, which often take longer to produce a complete answer from the NewAPI gateway. Once the relay disconnected too early, HermesAgent could only see Connection error, RemoteProtocolError, and then exhausted fallback attempts.
The important boundary is this: HermesAgent itself was not the thing that needed a patch, and the model provider was not the thing that was down. The bug was in the connection policy of an external component. I had mixed up connect timeout with the lifetime of the entire response stream. That makes long requests fail even when the upstream model is perfectly healthy.
The fix was straightforward once the layer boundary was clear: keep a short timeout only for the connection phase, then switch the socket into a blocking wait after the upstream link is established. I also made the relay a standalone persistent service instead of tying it to a temporary shell session. That keeps the workaround clean and keeps Hermes core upgrades separate.

Background
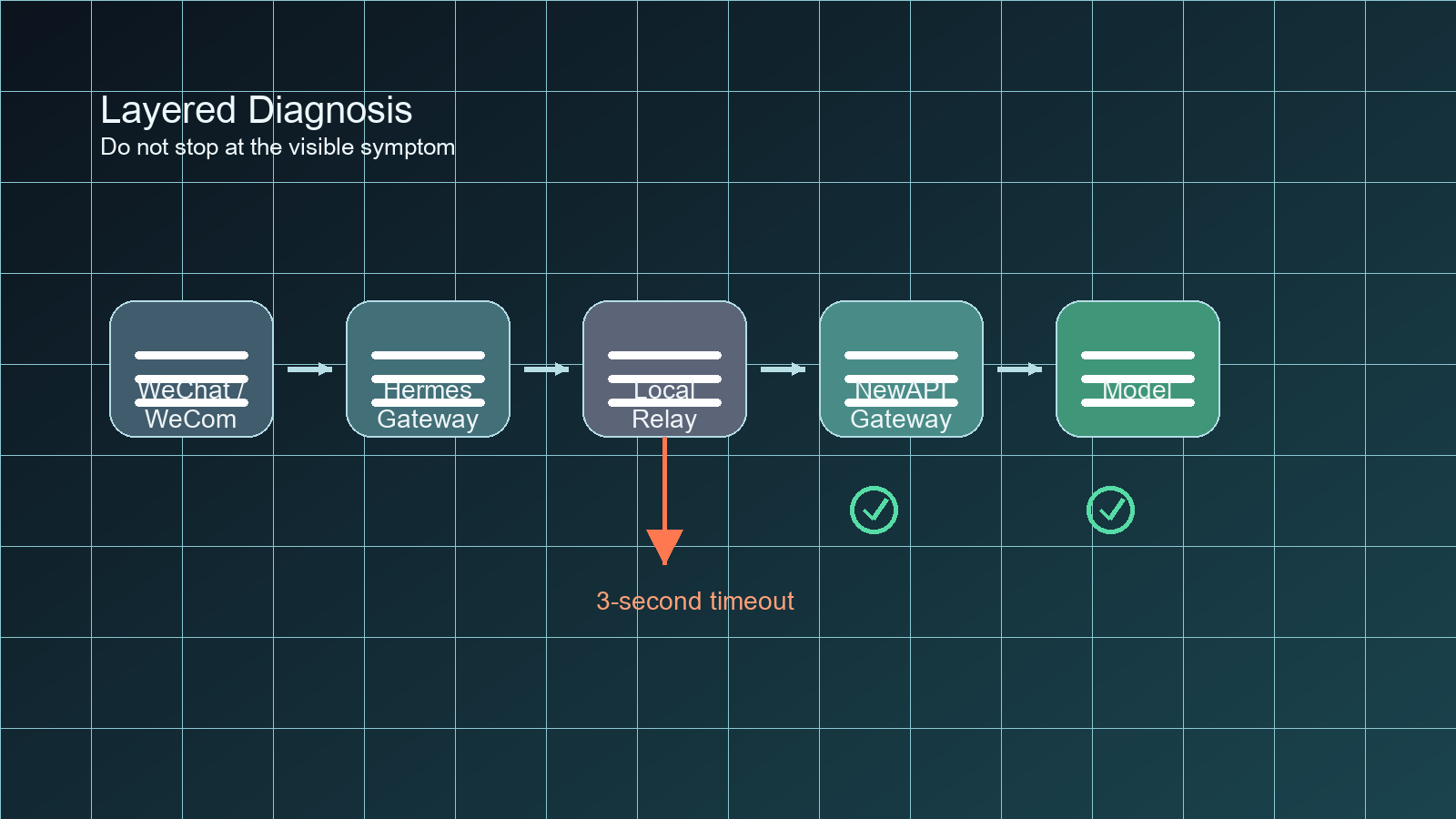
HermesAgent is not a single script sitting on a laptop. In this setup, a user message enters through WeChat or WeCom, passes into Hermes’ channel layer, then into the Gateway, then through a local relay, and only then reaches a self-hosted NewAPI gateway. The model’s answer then travels back through the same stack before the user sees it in chat.
That architecture is useful because it lets you swap providers and route traffic flexibly. It is also a perfect place for hidden failure modes. A user only sees a final symptom: “no reply” or a generic Connection error. The real cause could be in the channel, the gateway, the relay, a proxy, socket behavior, or the upstream model.
At first I also suspected model configuration. That was reasonable because the logs were noisy and the behavior looked like provider failure:
Primary model failed
switching to fallback
API failed after 1 retries
Connection error
Max retries exhausted
That kind of log text strongly suggests a model issue, but logs like these can be misleading. The same provider could still respond fine in a small probe. What matters is whether the full message turn can complete.
What the failure looked like
The symptom was consistent: messages sent from WeChat or WeCom would enter HermesAgent, but no answer would make it back. The system would try the primary model, then the fallback model, and both would fail with the same broad network-level error.
This is a crucial distinction. It was not a case of duplicated sends or repeated callbacks. It was a single turn that failed before the response could be fully collected. That tells you to inspect the response path, not the send path.
The failure chain looked like this:
- Hermes tried the primary provider.
- The request failed.
- Hermes switched to fallback.
- The fallback failed the same way.
- Hermes emitted a generic connection error.
The models themselves were not the problem. The relay was truncating the wait window before the model had enough time to finish a real response.
What I ruled out first
1. Not a model-list problem
I always start with the simplest health checks. The model list was reachable, and minimal requests worked. That ruled out a completely dead provider.
2. Not a duplicate-send problem
If the channel layer were sending the same message multiple times, I would have seen multiple replies or repeated callbacks. That was not the case. The failure happened inside a single request turn.
3. Not just a bad fallback choice
Fallbacks were part of the logs, but they were not the root cause. The fallback was being dragged into the same relay failure as the primary path. Changing models alone would not solve a transport problem.
4. Not a Hermes core bug
This is the part that matters for upgrades. The Hermes core did not need to be patched. The issue was outside the core, in the local relay and how it handled timing. That means core upgrades can stay normal, as long as the relay wrapper stays in place.
Debugging the stack layer by layer
The cleanest way to debug this kind of problem is to stop treating the stack as one blob and split it into layers.
Layer 1: the channel
The channel receives the user message and hands it to Hermes. Here, the only question is whether the message made it into the system at all.
Layer 2: the Gateway
The Gateway is where model selection, retries, fallback, and final response assembly happen. If this layer is wrong, you often see provider switches or repeated retries.
Layer 3: the local relay
The relay forwards Hermes traffic to my self-hosted NewAPI endpoint. It looks small, but it decides whether the upstream request can stay alive long enough to finish. In this incident, that was the real fault line.
Layer 4: upstream gateway and model
The upstream was fine. The model could answer. The problem was that the relay stopped waiting too early. A healthy upstream is useless if the proxy in front of it closes the connection prematurely.
The decisive test was to replay the same real request directly through the relay. It returned a normal 200 OK, but it took roughly 8 seconds. That was the proof I needed. The model was not failing instantly; it just needed longer than 3 seconds. The relay was the thing that was too impatient.

The actual root cause
The core engineering conclusion is simple:
I had accidentally used a 3-second timeout for the entire lifetime of the upstream request, when the request actually needed a longer response window.
The correct behavior is to separate the two phases:
- Use a short timeout for the connection phase so dead upstream hosts fail fast.
- After the connection is established, remove the response timeout so the model can finish naturally.
- Do not let the client treat a successful connection as if the whole request should already be done.
Without that separation, the relay can close the socket while the model is still generating the answer. Hermes then only sees a disconnected transport, not a complete response.
The relevant behavior ended up looking like this:
upstream = socket.create_connection((UPSTREAM_HOST, UPSTREAM_PORT), timeout=3)
upstream.settimeout(None)
client.settimeout(None)
The point of the code is not the syntax. The point is the boundary: short timeout for connect, blocking wait for response. For a chat relay that forwards real generation turns, that boundary matters.
Why I kept the relay as a persistent service
If the relay lives inside an ad hoc shell session, it can disappear because the shell closes, the environment changes, or the process gets cleaned up. That is a fragile setup for a message entry point.
I moved the relay into a dedicated long-running process so its lifecycle is separate from Hermes core. That has two practical benefits:
- Hermes can be upgraded without dragging the relay along with it.
- The relay’s environment, timeout rules, and logs are isolated and easier to inspect.
That separation is why I do not recommend pushing this kind of fix into Hermes core. Keep the core clean. Keep the transport shim outside. You will thank yourself the next time you upgrade.
There is also a practical observability benefit. A dedicated relay process gives you a stable PID, its own logs, and a clear start/stop boundary. When you are debugging a live message pipeline, that matters more than it looks on paper. A temporary shell session can hide the exact moment the relay was restarted, inherited the wrong environment, or lost its socket behavior. A standalone service makes those transitions explicit.
How I verified the fix
I did not stop at “the log looks better”. I checked the fix in layers:
- Confirm the upstream gateway still serves the model list.
- Verify that a minimal prompt returns normally.
- Replay the real WeChat / WeCom request turn through the relay.
- Check that the response now waits long enough to complete.
- Confirm that Hermes no longer emits
Connection error,RemoteProtocolError, or fallback exhaustion.
After the fix, the turn no longer died at the 3-second mark. The reply returned normally, and the user-facing channels started working again.
One subtle point is worth calling out: a 3-second limit is often enough to make a quick health probe look healthy, especially when you only test /v1/models or a tiny prompt. That is why this kind of bug can survive for a while. The path is “working” in the narrow sense that the socket connects and a trivial probe returns. It is only when the real turn has to wait for generation, tool routing, or a larger context window that the mistake becomes visible. In other words, the timeout was not obviously wrong until I tested the exact workload users actually send.

A practical checklist
If you hit a similar issue, I would troubleshoot in this order:
- Separate “multiple messages” from “no reply”.
- Test a minimal prompt before testing a real turn.
- Record the winner provider, model, retry count, and final error.
- Replay the exact request against the relay or upstream gateway.
- Check whether the timeout applies only to connect or to the entire response lifecycle.
- Make sure the relay is a real persistent service, not just a temporary shell process.
- Only after all that should you consider touching Hermes core.
That order matters because it quickly separates model problems from transport problems. In agent systems, the transport layer is often the hidden culprit.
Q&A
Q1: Was this a HermesAgent core bug?
No. The root cause was in the local relay’s connection policy. Hermes was only surfacing the error.
Q2: Will a normal Hermes upgrade overwrite the fix?
Not if the fix stays in the external relay wrapper and its startup configuration. The core can be upgraded normally. The only thing to re-check afterward is that the relay still starts with the same timeout and environment rules.
Q3: Why did curl look fine while real messages failed?
Because curl usually tests a short, simple request. A real message turn can include context, tool calls, and longer generation time. Fast success on a trivial probe does not prove that the full turn will survive.
Q4: Why not just increase the timeout and be done with it?
Because you should separate connection timeout from response waiting. If you stretch everything indiscriminately, you can hide real network issues and make debugging harder. The correct fix is to time-box connection establishment, not the whole response lifecycle.
Q5: Can a prompt fix this?
No. A prompt cannot stop a socket from being closed too early. This was a transport issue, not a language issue.
Q6: What should I preserve if I want to upgrade Hermes normally?
Preserve the external relay wrapper and its startup definition. That includes the timeout split, the environment you launch it under, and the fact that it runs independently from Hermes core. If you keep those pieces separate, upgrading Hermes itself should stay routine. The upgrade does not need to know about this transport workaround, and the workaround does not need to live inside Hermes source code. That separation is the whole point.
References
- Apple launchd.plist documentation:
https://developer.apple.com/library/archive/documentation/MacOSX/Conceptual/BPSystemStartup/Chapters/CreatingLaunchdJobs.html - HTTPX timeout and exception docs:
https://www.python-httpx.org/advanced/timeouts/andhttps://www.python-httpx.org/exceptions/ - tmux manual:
https://man7.org/linux/man-pages/man1/tmux.1.html