HermesAgent 为什么一直不回微信和企业微信?我最后排到的根因居然是本地 relay 的 3 秒超时
先说结论
这次故障看起来像“模型不行”或者“微信通道坏了”,但真正把消息链路掐断的,是我本地那层 relay 的超时设置。它把整条上游请求的等待窗口限制成了 3 秒,而真实的 WeChat / WeCom 消息 turn 往往需要更久才能从新 API 网关拿到完整回复。结果就是:relay 先断开,HermesAgent 只能看到 Connection error、RemoteProtocolError,然后主模型和 fallback 一起被耗尽。
更准确地说,这不是 HermesAgent 核心代码的问题,也不是模型名的问题,而是一个本地外置组件的连接策略问题。把 connect timeout 和 response wait 混成同一个超时,等于给长请求做了一个错误的截止时间。修复方式也不复杂:连接阶段保留短超时,连接成功后把 socket 切回阻塞等待;同时把 relay 做成独立、可持续启动的服务,不再把它绑死在临时 shell 里。

问题背景
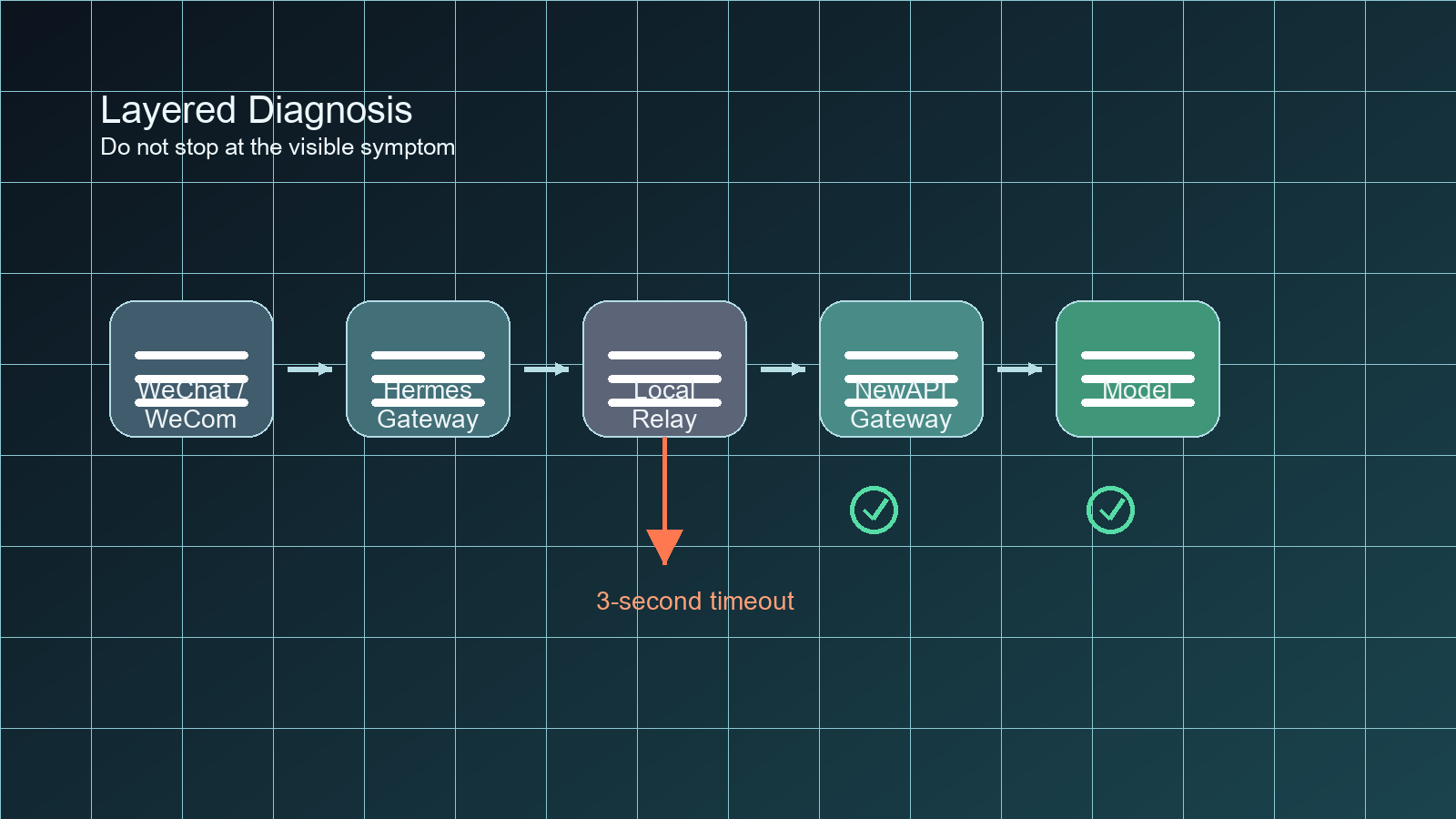
HermesAgent 这条链路不是单机脚本,而是一条完整的消息生产线。用户从微信或企业微信发出一句话,消息会先进入 Hermes 的通道层,再进入 Gateway,接着经过本地 relay 转发到自建的 NewAPI 网关,最后才到模型服务。模型回来的内容还要经过 Hermes 的消息整理、工具调用处理、最终拼接,再发回原始通道。
这种结构的好处是灵活,坏处也很现实:任何一层都可能制造“看起来像模型故障”的表象。你看到的是“没有回复”或者“Connection error”,但根因可能在更外层的 relay、socket、超时、代理或者会话路由里。
这次我一开始也走了老路,先怀疑模型配置。因为从表象看,主模型和 fallback 都失败了,日志里反复出现:
Primary model failed
switching to fallback
API failed after 1 retries
Connection error
Max retries exhausted
如果你只看这一段,很容易得出“模型端不稳定”的结论。但这类结论通常太早。因为同一批模型在别的入口上是能正常工作的,/v1/models 也能返回,简单的 health check 也没有异常。真正出问题的是“真实消息 turn”。
问题表现
故障的表现很统一:不管是微信还是企业微信,只要通过 HermesAgent 发起一次真实对话,请求就会在链路中断掉。表面上看是模型连不上,但更贴近真实情况的描述是:消息已经进入 Hermes 了,路也选对了,最后一层 relay 却在等待完整响应之前把连接掐掉了。
这种中断会带来几个副作用:
- 主模型先报错。
- fallback 接着被尝试。
- fallback 也报错。
- Hermes 最后只剩下一个泛化后的
Connection error。
如果你在这个阶段只盯着模型名,就会忽略一个关键事实:错误发生在请求生命周期里,而不是“模型不可用”的那种静态失败。也就是说,模型可能是健康的,只是你的 relay 没有等到它把话说完。
我先排除了哪些假设
1. 不是模型列表问题
先看模型列表和最小请求,是为了确认上游是不是已经挂掉。这个步骤很重要,因为很多“回复不上”的问题其实只是模型配置错了、鉴权错了、或 provider 名称写错了。但这里 /v1/models 正常,最小 Reply exactly: OK 也能成功。说明模型层面并没有完全失联。
2. 不是通道重复发送
故障不是“微信发了两次”或者“企业微信重复回调”。如果是这个问题,你通常会看到多条重复消息,或者队列消费两次。这里不是。这里是单次消息 turn 直接失败,说明要重点看 response path 而不是 send path。
3. 不是纯粹的 fallback 选择错误
fallback 本身也不是根因。因为我测到的问题不是“某个备用模型不好用”,而是只要走这条 relay,长一点的真实 turn 就会失败。换句话说,fallback 只是被同一个底层故障一起拖下水了。
4. 不是 Hermes 核心需要补丁
这是一个很重要的边界。HermesAgent 核心本身可以继续正常升级;这次问题发生在外部 relay,而不是框架内核。也就是说,不需要为了修这次故障去改 Hermes 的核心源码,更不需要把这类连通性问题硬塞到 agent 主仓里。
分层排障:问题到底卡在哪一层
这类问题最好像排生产链路一样拆层看。
第一层:通道层
通道层负责接收消息、组织消息上下文、把用户输入交给 Hermes。这里的关键不是“有没有收到消息”,而是“收到以后有没有把它送到下游”。
第二层:Gateway 层
Gateway 层负责模型路由、会话管理、fallback 和最终响应调度。如果这里出问题,日志通常会出现 provider 切换、重试耗尽、或者最终输出异常。
第三层:relay 层
relay 层负责把 Hermes 的请求转发到自建 NewAPI 网关。它看起来只是一层薄代理,但实际上它决定了请求连接的生死。如果 relay 把等待响应的时间窗口设错,前两层都只是“看起来正常”。
第四层:上游网关和模型层
这层负责最终的模型响应。它们本身是健康的,但如果上层在 3 秒内就断开连接,模型再健康也没机会把结果完整返回。
我真正确认问题的方式,不是只看 Hermes 里那条外层错误,而是把同一份真实请求重放到 relay,上游直接返回大约 8 秒的正常响应。这个对照非常关键。它说明模型不是立刻失败,而是“有点慢,但能工作”;失败的是 relay 这层的等待方式。

真正根因:把连接超时当成了整条请求超时
这次问题最核心的一句工程结论是:
relay 的
timeout=3被错误地放大成了整条请求的生存时间,而真实的消息 turn 需要更长的等待窗口。
我后来把 relay 的行为拆开后,问题就非常清楚了。正确的做法不是“所有 socket 都只等 3 秒”,而是:
- 连接阶段可以保持一个较短的超时,用来快速发现上游不可达。
- 一旦连接建立成功,就应该把 socket 切回不带超时的等待状态,允许模型完整返回。
- 客户端侧也不要因为连接成功就提前认定请求该结束。
如果把这三步混在一起,relay 就会在上游还在正常生成内容的时候主动断开。Hermes 看到的自然就是一个断掉的连接,而不是一个完整的 200 OK。
我最后把代码调整成了这种逻辑:
upstream = socket.create_connection((UPSTREAM_HOST, UPSTREAM_PORT), timeout=3)
upstream.settimeout(None)
client.settimeout(None)
重点不是这几行代码本身,而是它表达的边界:连接阶段短超时,数据阶段无限等待。对这种会产生真实生成时长的消息代理来说,这个边界是必须明确的。
我为什么还把 relay 独立成常驻服务
如果 relay 只是临时 shell 里跑着,那它总有一天会因为退出、环境变化、窗口关闭或者会话清理而中断。对一个要处理微信和企业微信消息的入口来说,这种运行方式不够稳定。
所以我把 relay 独立成了一个长期常驻的进程,让它的生命周期和 Hermes 核心分开。这样做有两个直接好处:
- Hermes 升级的时候,不会把 relay 一起带崩。
- relay 的环境变量、超时和日志都能单独看,定位问题更干净。
这也是为什么我不建议把这类修复硬塞进 Hermes 核心。核心保持干净,外置兼容层和转发层单独维护,后续升级会轻松很多。
怎么验证修复是真的生效
我不是只看“没有报错”就结束,而是按下面几步验证:
- 先确认上游网关正常返回模型列表。
- 再用最小 prompt 验证简单请求可以返回。
- 再把真实的微信 / 企业微信消息 turn 重放到 relay。
- 观察响应是否能够完整等待到模型返回。
- 看 Hermes 里是否还会出现
Connection error、RemoteProtocolError或 fallback 耗尽。
修复后,真实消息 turn 不再在 3 秒时被截断,而是可以稳定等到上游返回。也就是说,失败不再出现在 relay 层,Hermes 也终于能正常把回复发回微信和企业微信。

一个实用的排障清单
如果你也遇到类似问题,我建议按这个顺序查:
- 先区分“多条重复消息”和“一条消息没回复”。
- 先看最小请求是否成功,再看真实消息 turn。
- 记录 winner provider、model、重试次数和最终错误。
- 把真实请求重放到 relay 或网关,确认是连接失败还是响应等待失败。
- 看 socket 的 timeout 是不是只应该作用在 connect,而不是整个 response 生命周期。
- 确认 relay 是不是一个真正独立、可持续运行的服务。
- 最后再决定要不要碰 Hermes 核心代码。
这个顺序的价值在于,它能让你尽快区分“模型问题”和“链路问题”。在 Agent 系统里,这个区分很重要,因为很多问题看起来像模型,实际上都不是模型。
Q&A
Q1:这次问题是 HermesAgent 核心 bug 吗?
不是。根因在本地 relay 的连接策略,而不是 Hermes 核心本身。Hermes 只是把底层错误向上包装了出来。
Q2:那我以后升级 Hermes,会不会把修复冲掉?
如果你的修复也只是外置 relay 的配置和运行方式,那 Hermes 核心升级不应该影响它。真正要注意的是:升级后别忘了重新确认 relay 的启动方式、环境变量和超时逻辑。
Q3:为什么 curl 看起来没问题,真实消息却失败?
因为 curl 往往测的是一个很小的、很短的请求。真实消息 turn 可能带上下文、工具调用和更长的生成时间。短请求能过,不代表长请求也能过。
Q4:为什么不直接把 timeout 调大一点就完了?
这要分清楚是 connect timeout 还是 response wait timeout。把所有阶段都拉长,可能只是掩盖连接问题;把 connect 超时和响应等待分开,才是更稳的办法。
Q5:能不能用 prompt 解决?
不能。prompt 解决不了 socket 提前断开,也解决不了 relay 主动关闭连接。这个问题是链路问题,不是语言问题。
参考资料
- Apple
launchd.plistdocumentation:https://developer.apple.com/library/archive/documentation/MacOSX/Conceptual/BPSystemStartup/Chapters/CreatingLaunchdJobs.html - HTTPX timeout and exception documentation:
https://www.python-httpx.org/advanced/timeouts/andhttps://www.python-httpx.org/exceptions/ - tmux manual:
https://man7.org/linux/man-pages/man1/tmux.1.html