ProxmoxVE 添加 local-lvm 使用率监控、网线速率监控到 Uptime Kuma
先说结论
ProxmoxVE 的
local-lvm不是一个普通挂载目录,很多时候不能靠df -h发现它快满了;网口协商速率也不会因为服务还在线就自动暴露出来。最稳的办法是把这两个“容易被忽略但一出事就很麻烦”的指标接入现有 Uptime Kuma:local-lvm用 HTTP 拉取监控,网口速率用 Push 主动上报。这样磁盘池接近阈值、网线或交换机端口掉到百兆时,统一在 Uptime Kuma 页面和通知链路里告警。
本文会从需求背景、原始方案的问题核查、改进后的脚本、systemd 服务、Uptime Kuma 配置、验证方法和安全边界讲完整。文中所有地址、token、主机名都使用占位符,不出现真实内网信息。你可以把示例里的 <PVE_HOST>、<KUMA_URL>、<PUSH_TOKEN>、<INTERFACE> 替换成自己的环境值。
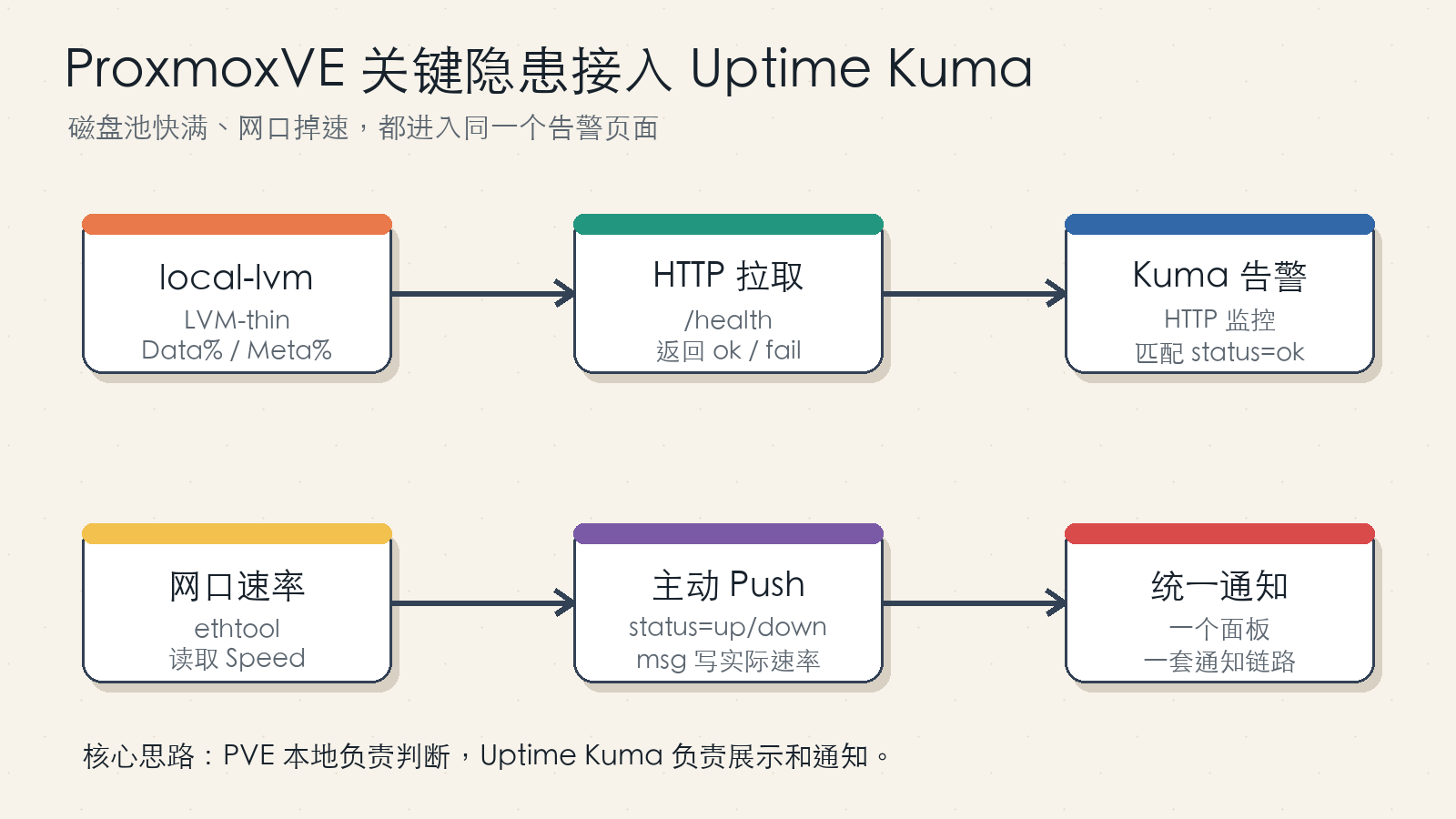
图 1:全文概要。磁盘监控由 Uptime Kuma 定时拉取 PVE 上的 HTTP 检查服务;网口速率由 PVE 定时主动 Push 到 Uptime Kuma。
1. 为什么要专门监控 local-lvm 和网口速率
很多故障并不是“整台机器宕机”这么干脆。更常见的是:页面还能打开,部分任务失败;数据库还能连,但写入开始报错;虚拟机还在跑,备份或快照却突然失败;NAS 还能访问,但大文件传输从一百多 MB/s 掉到十 MB/s 左右。排查这种问题时,人很容易先怀疑应用、数据库、网络协议、权限、缓存,最后才发现是存储池满了,或者网口只协商到了百兆。
这两个问题有共同点:
- 它们不会总是表现为“服务不可用”。
- 它们的根因在基础设施层,应用层日志经常只显示间接错误。
- 它们很适合提前告警,因为指标非常明确。
- 它们又太小众,通常不值得单独上 Prometheus、Grafana、node exporter 全家桶。
如果家里或小团队已经在用 Uptime Kuma 监控站点、端口、证书和服务存活,把这些基础设施小指标塞进 Uptime Kuma 是很合适的:页面统一、通知统一、维护成本低。它不是专业指标平台,但做“阈值型健康检查”已经够用。
本文目标不是把 Uptime Kuma 改造成监控平台,而是补上两个实际缺口:
- ProxmoxVE 的
local-lvmthin pool 使用率超过阈值时告警。 - 指定网口没有达到预期链路速率时告警。
2. 先核查原始思路里容易踩坑的地方
原始方案的方向是对的:local-lvm 用 PVE 暴露一个 HTTP 接口给 Uptime Kuma 拉取,网口速率用脚本主动调用 Uptime Kuma Push URL。但是直接照搬会有几个问题。
2.1 只看 HTTP 200 不够
如果 Python HTTP 服务永远返回 200,即使 JSON 里写了 "status":"fail",普通 HTTP 监控也可能仍然认为它是正常的。解决办法有两个:
- HTTP 服务在异常时返回
503。 - Uptime Kuma HTTP 监控同时配置关键字,例如匹配
"status":"ok"。
我更推荐两个都做。HTTP 状态码负责粗粒度失败,关键字匹配负责避免脚本输出异常但状态码仍为 200 的情况。
2.2 LVM thin pool 不能只看 Data%
LVM thin pool 有数据区和元数据区。Data% 接近 100% 会出问题,Meta% 接近 100% 同样危险。原始脚本只看 data_percent,容易漏掉元数据耗尽的场景。LVM 官方手册也明确建议在 thin pool 上关注 data_percent 与 metadata_percent,并在它们接近 100% 前扩容。
所以本文的检查规则是:任一 thin pool 的 Data% 或 Meta% 达到阈值,就判定 fail。
2.3 pool_lv 过滤条件不够稳
原始脚本用 pool_lv == data 来过滤逻辑卷。这个假设只适用于某些默认安装或特定命名。更稳的方式是直接从 lvs 输出中识别 thin pool LV,并读取它自己的 data_percent 与 metadata_percent。如果你的环境确实只想监控某个池,也可以再加白名单变量,例如 WATCH_LV=data。
2.4 curl URL 拼接需要处理特殊字符
网口速率脚本里如果把 msg=Speed is 100Mb/s 直接拼进 URL,空格、斜杠、冒号都可能引起转义问题。应使用 curl --get --data-urlencode 传参。这样 Uptime Kuma 里能看到清楚的消息,脚本也不会因为消息文本变复杂而失效。
2.5 Push token 不能写进公开文章
Uptime Kuma Push URL 里的 token 等价于这个监控项的写入凭证。任何拿到 token 的人都可以把监控上报成 up 或 down。公开文章、截图、仓库里都不应该出现真实 token。本文统一使用 <PUSH_TOKEN> 占位。
3. 两种监控模式怎么选
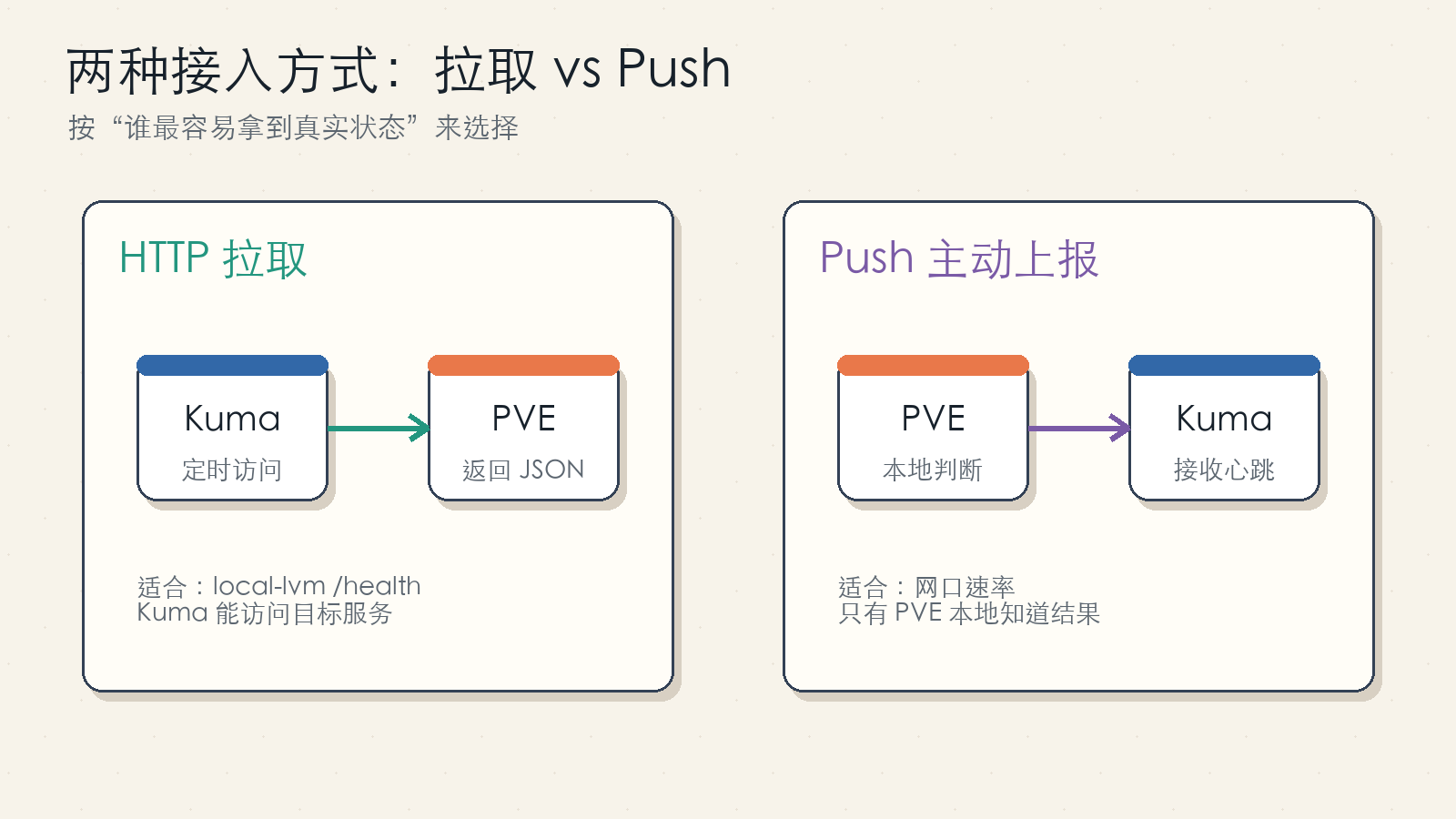
图 2:能被 Uptime Kuma 访问到的检查项适合 HTTP 拉取;只能在被监控机器本地判断的状态适合 Push。
local-lvm 监控采用“被动调用”或“拉取”:PVE 上运行一个只读检查服务,Uptime Kuma 定时访问 http://<PVE_HOST>:8080/health。这样 Uptime Kuma 可以自己决定检查频率、重试次数、告警策略。
网口速率采用“主动调用”或“Push”:PVE 本地通过 ethtool 读取指定网卡当前协商速率,然后调用 Uptime Kuma 的 /api/push/<token>。因为网口速率是主机本地状态,而且很多情况下 Uptime Kuma 所在机器不能直接知道远端网卡协商结果,所以 Push 更自然。
这两种模式可以总结为:
- Uptime Kuma 能直接访问,并且检查动作很轻量:用 HTTP 拉取。
- 只有被监控机器自己知道结果,或需要本地命令判断:用 Push。
4. local-lvm 为什么不能靠 df -h
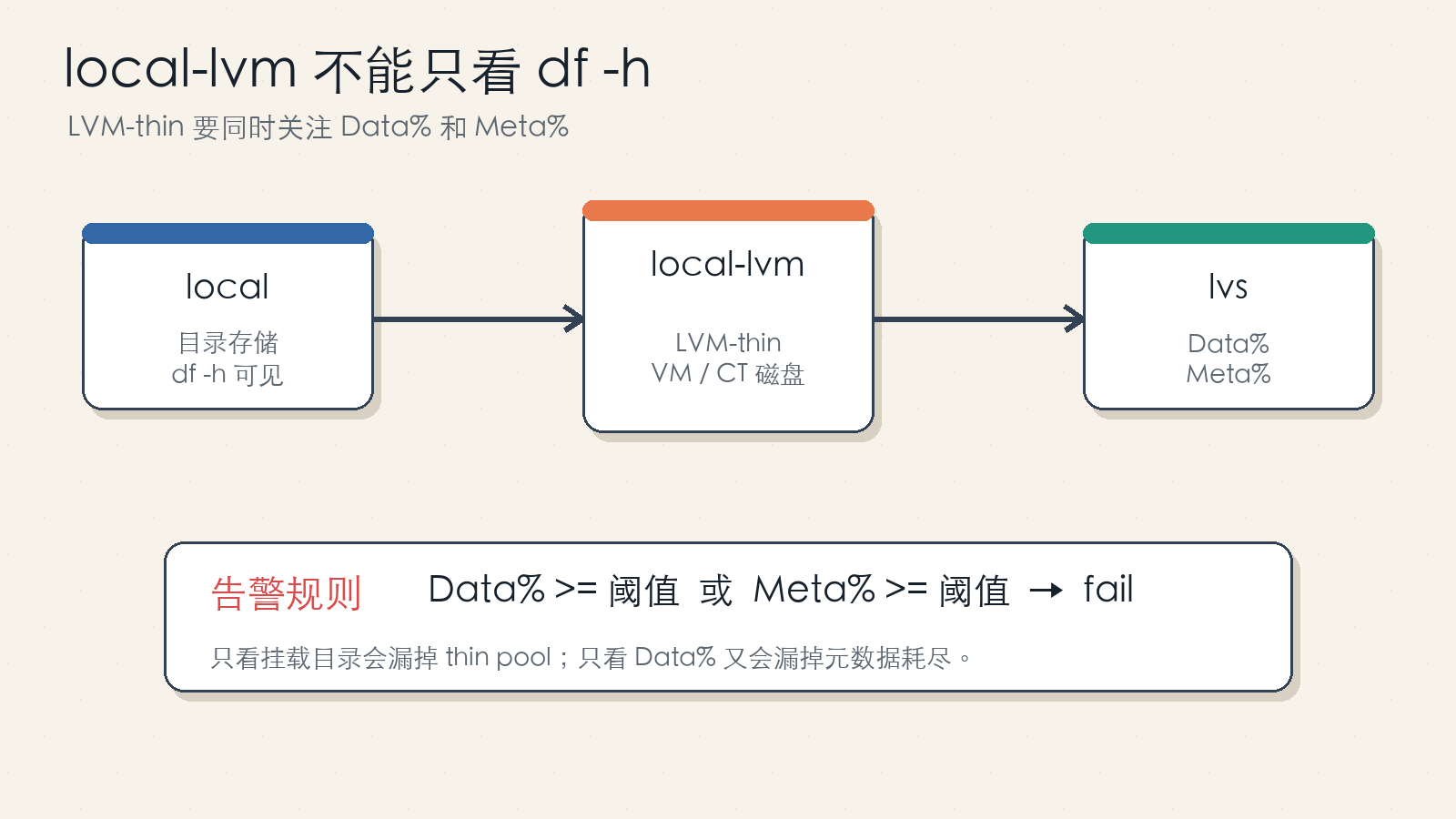
图 3:local 常见是目录存储,local-lvm 常见是 LVM-thin 块存储;后者要用 lvs 查看 thin pool 指标。
ProxmoxVE 默认安装时经常会出现两个本地存储:
local:目录存储,通常用于 ISO、模板、备份片段等。local-lvm:LVM-thin 存储,通常用于 VM 磁盘和 CT rootfs。
local 是文件系统目录,df -h 很直观。local-lvm 是 thin pool,虚拟磁盘以逻辑卷形式存在,不能把它当成一个普通目录看。你需要用类似下面的命令查看:
lvs -o lv_name,vg_name,lv_size,data_percent,metadata_percent,lv_attr,pool_lv
如果只看 PVE 页面,当然也能看到一部分信息;但监控系统需要稳定、可脚本化、可返回机器可读结果,所以这里选择直接调用 lvs。
5. 改进版 LVM 检查脚本
下面脚本建议保存为 /usr/local/bin/lvm_check.sh,并授予执行权限。它使用 lvs --reportformat json 和 jq,避免手工按空格切字段导致解析不稳定。
#!/usr/bin/env bash
set -euo pipefail
THRESHOLD="${THRESHOLD:-90}"
LVS_BIN="${LVS_BIN:-/sbin/lvs}"
if ! command -v jq >/dev/null 2>&1; then
echo '{"status":"fail","error":"jq is required"}'
exit 2
fi
"$LVS_BIN" --reportformat json --units g --nosuffix \
-o lv_name,vg_name,lv_size,data_percent,metadata_percent,lv_attr,pool_lv |
jq --argjson threshold "$THRESHOLD" '
.report[0].lv
| map(select(((.lv_attr // "") | startswith("t")) or ((.data_percent // "") != "" and (.metadata_percent // "") != "")))
| map({
lv: .lv_name,
vg: .vg_name,
size_g: .lv_size,
data_percent: ((.data_percent // "0") | tonumber),
metadata_percent: ((.metadata_percent // "0") | tonumber)
})
| {
status: (if any(.[]; .data_percent >= $threshold or .metadata_percent >= $threshold) then "fail" else "ok" end),
threshold: $threshold,
volumes: map(select(.data_percent >= $threshold or .metadata_percent >= $threshold))
}
'
安装依赖和授权:
apt update
apt install -y jq
install -m 0755 lvm_check.sh /usr/local/bin/lvm_check.sh
正常时输出类似:
{
"status": "ok",
"threshold": 90,
"volumes": []
}
超过阈值时输出类似:
{
"status": "fail",
"threshold": 90,
"volumes": [
{
"lv": "data",
"vg": "pve",
"size_g": "900.00",
"data_percent": 93.2,
"metadata_percent": 41.8
}
]
}
注意,这里的示例卷名和容量只是示意,不代表任何真实机器。
6. LVM HTTP 检查服务
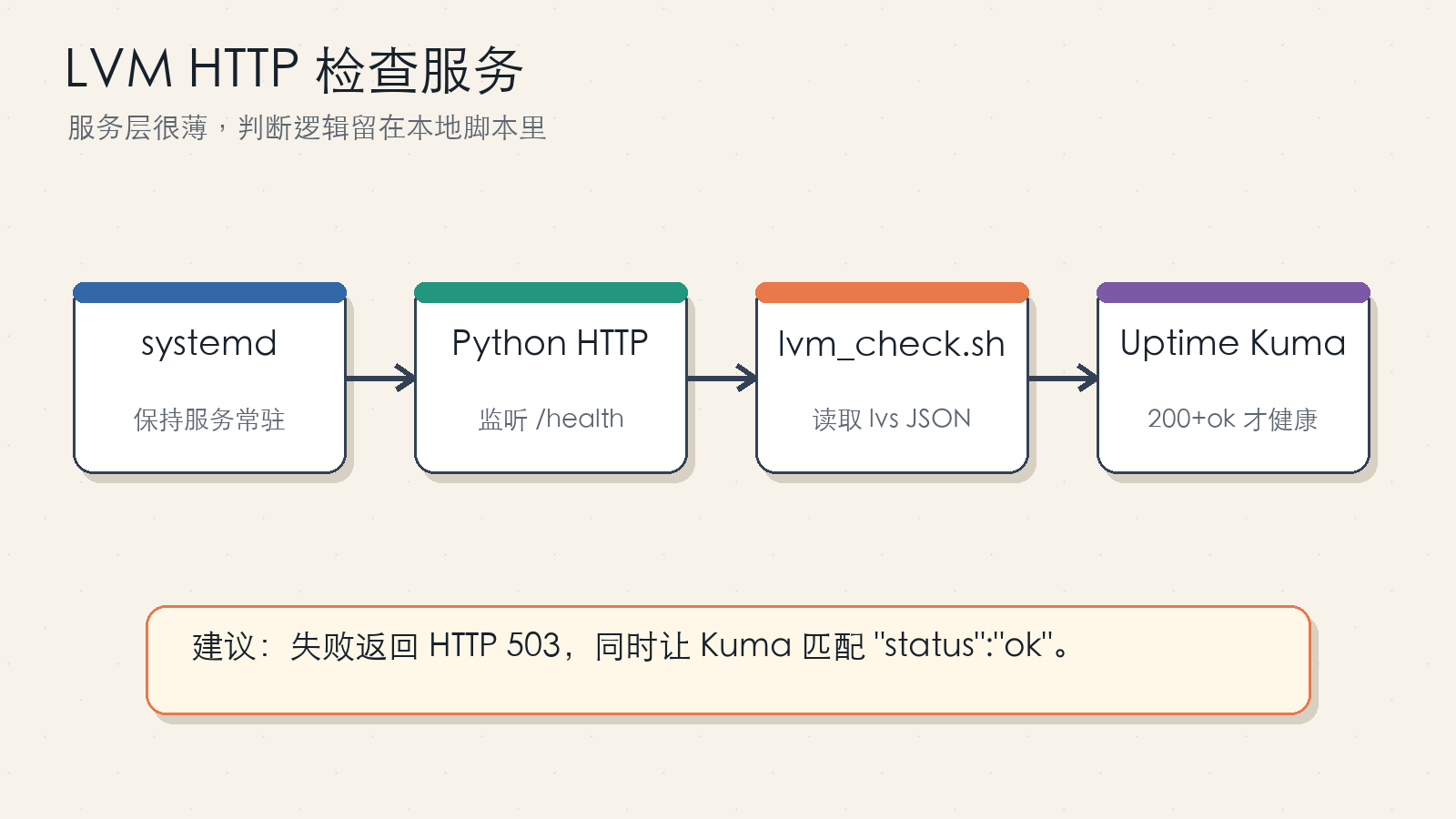
图 4:HTTP 服务只是一个薄封装,真正的判断仍然放在本地脚本里,方便单独测试和替换。
下面的 Python HTTP 服务建议保存为 /root/TOOLS/lvm_http_server.py。它只处理 /health,脚本失败或 JSON 状态为 fail 时返回 503,正常时返回 200。
#!/usr/bin/env python3
from http.server import BaseHTTPRequestHandler, HTTPServer
import json
import subprocess
CHECK_CMD = ["/usr/local/bin/lvm_check.sh"]
class LVMCheckHandler(BaseHTTPRequestHandler):
def log_message(self, fmt, *args):
return
def do_GET(self):
if self.path not in ("/", "/health"):
self.send_response(404)
self.end_headers()
self.wfile.write(b"not found\n")
return
result = subprocess.run(CHECK_CMD, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
body = result.stdout.strip() or '{"status":"fail","error":"empty output"}'
status_code = 200
try:
payload = json.loads(body)
if result.returncode != 0 or payload.get("status") != "ok":
status_code = 503
except json.JSONDecodeError:
status_code = 503
body = json.dumps({"status": "fail", "error": "invalid json from lvm_check.sh"})
self.send_response(status_code)
self.send_header("Content-Type", "application/json; charset=utf-8")
self.end_headers()
self.wfile.write((body + "\n").encode("utf-8"))
if __name__ == "__main__":
HTTPServer(("0.0.0.0", 8080), LVMCheckHandler).serve_forever()
systemd 服务文件 /etc/systemd/system/lvm-http.service:
[Unit]
Description=ProxmoxVE LVM thin pool health HTTP service
After=network-online.target
Wants=network-online.target
[Service]
Type=simple
ExecStart=/usr/bin/python3 /root/TOOLS/lvm_http_server.py
Restart=always
RestartSec=5
User=root
[Install]
WantedBy=multi-user.target
启用服务:
systemctl daemon-reload
systemctl enable --now lvm-http.service
systemctl status lvm-http.service --no-pager
curl -sS http://127.0.0.1:8080/health
如果 PVE 开了防火墙,只允许 Uptime Kuma 所在机器访问 8080 即可;如果你习惯只开放反向代理,也可以把这个服务绑定到 127.0.0.1,再由内网反向代理转发。核心原则是:这个接口只暴露健康状态,不暴露真实内网拓扑、token 或敏感路径。
7. Uptime Kuma 里配置 local-lvm HTTP 监控
在 Uptime Kuma 新增一个 HTTP(s) 监控:
- Monitor Type 选择
HTTP(s)。 - URL 填
http://<PVE_HOST>:8080/health。 - Method 使用
GET。 - Keyword 可以填
"status":"ok",如果你的 JSON 输出带空格,也可以填"status": "ok"。 - Heartbeat Interval 按重要性设置,例如 60 秒或 300 秒。
- Retries 建议大于 1,避免短暂服务重启误报。
- 通知渠道复用现有告警渠道。
这里有一个细节:如果 Python 服务已经在失败时返回 503,关键字匹配不是必需的,但我仍然建议配置。因为这样可以防止某次脚本异常输出了非预期 HTML、报错文本或空内容,却因为某层代理返回了 200 而被误判健康。
8. 网口速率监控脚本
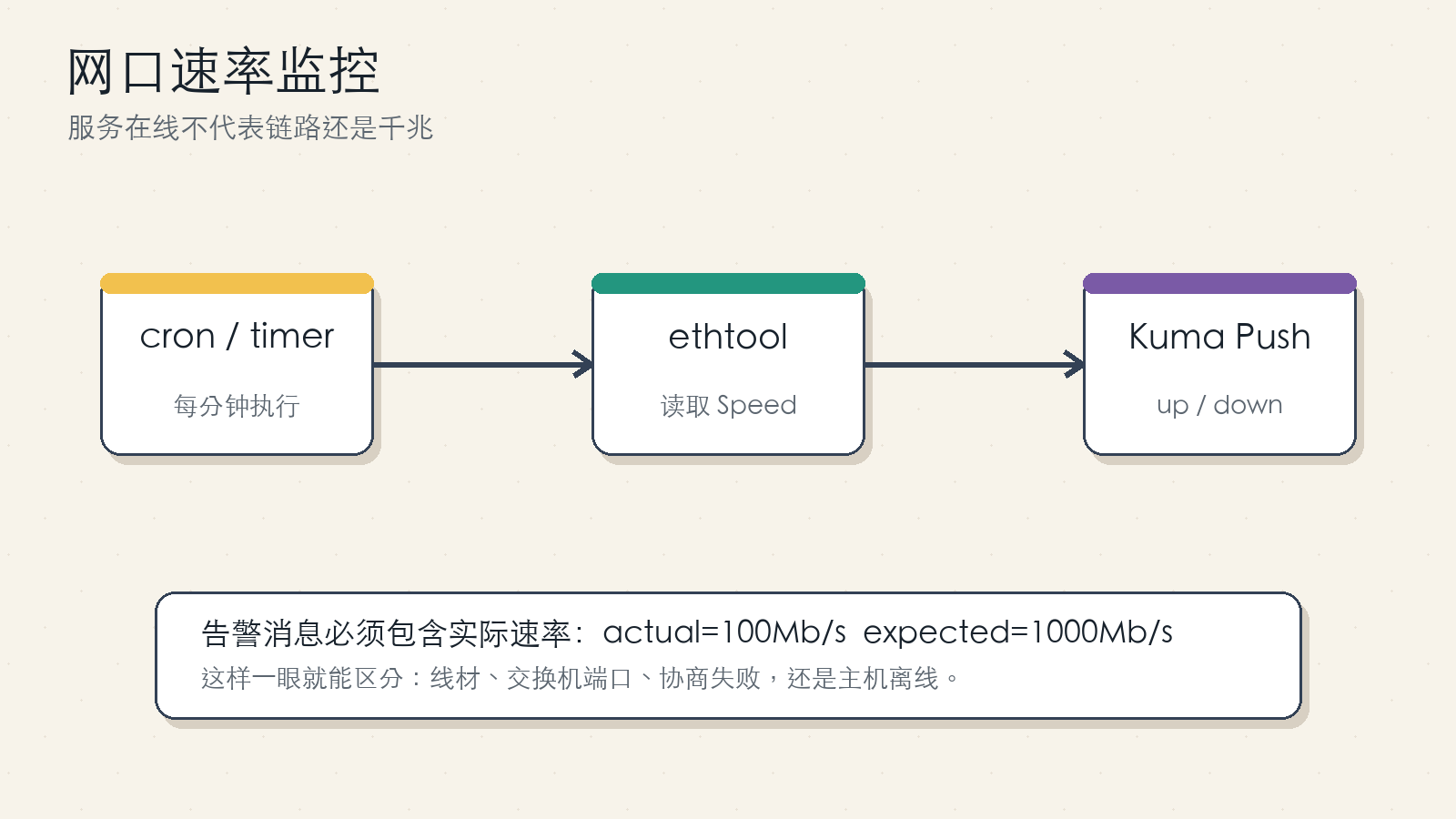
图 5:链路速率检查适合 Push。告警消息里应带上实际速率,方便直接定位线材、交换机端口或协商问题。
网口速率问题的典型表现是:服务都在,Ping 也正常,但大文件传输速度只有十 MB/s 左右。这个时候通常要检查网线、交换机端口、光猫/软路由口、网卡驱动、EEE 节能协商等。监控脚本不负责修复,只负责在速率偏离预期时第一时间告诉你。
建议脚本保存为 /usr/local/bin/lan_speed_checker.sh:
#!/usr/bin/env bash
set -euo pipefail
INTERFACE="${INTERFACE:-<INTERFACE>}"
EXPECTED_SPEED="${EXPECTED_SPEED:-1000Mb/s}"
PUSH_URL="${PUSH_URL:-https://<KUMA_URL>/api/push/<PUSH_TOKEN>}"
if ! command -v ethtool >/dev/null 2>&1; then
STATUS="down"
MSG="ethtool not installed"
PING="0"
else
SPEED="$(ethtool "$INTERFACE" 2>/dev/null | awk -F': ' '/Speed:/ {print $2; exit}')"
SPEED="${SPEED:-unknown}"
if [ "$SPEED" = "$EXPECTED_SPEED" ]; then
STATUS="up"
MSG="link speed ok: ${INTERFACE} ${SPEED}"
PING="1"
else
STATUS="down"
MSG="link speed abnormal: ${INTERFACE} actual=${SPEED} expected=${EXPECTED_SPEED}"
PING="0"
fi
fi
curl -fsS --get "$PUSH_URL" \
--data-urlencode "status=${STATUS}" \
--data-urlencode "msg=${MSG}" \
--data-urlencode "ping=${PING}" >/dev/null
安装依赖和授权:
apt update
apt install -y ethtool curl
install -m 0755 lan_speed_checker.sh /usr/local/bin/lan_speed_checker.sh
手动测试时不要急着写 crontab,先显式传入变量:
INTERFACE="<INTERFACE>" \
EXPECTED_SPEED="1000Mb/s" \
PUSH_URL="https://<KUMA_URL>/api/push/<PUSH_TOKEN>" \
/usr/local/bin/lan_speed_checker.sh
如果你有 2.5G、5G 或 10G 网络,把 EXPECTED_SPEED 改成对应值即可,例如 2500Mb/s 或 10000Mb/s。不要把“千兆”写死在脚本里,否则以后升级交换机或网卡时容易忘记改。
9. 用 cron 或 systemd timer 定时执行
最简单可以用 cron:
PATH=/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/sbin:/usr/local/bin
* * * * * INTERFACE=<INTERFACE> EXPECTED_SPEED=1000Mb/s PUSH_URL=https://<KUMA_URL>/api/push/<PUSH_TOKEN> /usr/local/bin/lan_speed_checker.sh
如果你不想把 Push URL 直接写在 crontab 里,可以放到 root 可读的环境文件,例如 /etc/default/lan-speed-checker:
INTERFACE=<INTERFACE>
EXPECTED_SPEED=1000Mb/s
PUSH_URL=https://<KUMA_URL>/api/push/<PUSH_TOKEN>
然后写一个 systemd service 和 timer。service:
[Unit]
Description=Push network link speed status to Uptime Kuma
[Service]
Type=oneshot
EnvironmentFile=/etc/default/lan-speed-checker
ExecStart=/usr/local/bin/lan_speed_checker.sh
timer:
[Unit]
Description=Run link speed checker every minute
[Timer]
OnBootSec=30
OnUnitActiveSec=60
AccuracySec=10
Unit=lan-speed-checker.service
[Install]
WantedBy=timers.target
启用:
systemctl daemon-reload
systemctl enable --now lan-speed-checker.timer
systemctl list-timers --all | grep lan-speed-checker
cron 简单直接,systemd timer 更容易查日志。家庭环境用 cron 完全可以;多台机器统一维护时,我更偏向 systemd timer。
10. Uptime Kuma 里配置网口 Push 监控
新增监控时选择 Push 类型。保存后,Uptime Kuma 会生成一个 Push URL,形式类似:
https://<KUMA_URL>/api/push/<PUSH_TOKEN>?status=up&msg=OK&ping=
脚本里只保留基础 URL:
https://<KUMA_URL>/api/push/<PUSH_TOKEN>
然后由 curl --data-urlencode 添加 status、msg、ping。Push 监控的重点配置是 Heartbeat Interval。假设脚本每分钟执行一次,Uptime Kuma 的心跳间隔可以设置为 60 秒,再给一点 Grace Period。这样脚本没执行、主机断网、Uptime Kuma 收不到上报,都会变成 down。
这里要理解一个区别:
status=down:脚本执行了,并明确告诉 Uptime Kuma 当前速率异常。- 没有收到 Push:脚本没执行、主机离线、网络断开、token 错误、Uptime Kuma 不可达,都可能导致超时。
这两种在告警上都重要,但排查方向不同。前者看网线、交换机、网卡协商;后者先看主机和任务是否还活着。
11. 验证清单
上线前建议按下面顺序验证。
11.1 验证 LVM 检查
/usr/local/bin/lvm_check.sh | jq .
curl -i http://127.0.0.1:8080/health
systemctl status lvm-http.service --no-pager
你应该看到:
- JSON 能被
jq正常解析。 - 正常时 HTTP 状态码为 200。
status为ok。- Uptime Kuma 的 HTTP 监控显示 up。
如果想测试 fail 分支,可以临时把阈值调低运行脚本:
THRESHOLD=1 /usr/local/bin/lvm_check.sh
不要为了测试真的把磁盘写满。
11.2 验证网口速率检查
ethtool <INTERFACE> | grep -E 'Speed|Duplex|Link detected'
INTERFACE=<INTERFACE> EXPECTED_SPEED=1000Mb/s PUSH_URL=https://<KUMA_URL>/api/push/<PUSH_TOKEN> /usr/local/bin/lan_speed_checker.sh
再到 Uptime Kuma 的 Push 监控页面看最近一次 heartbeat。建议把 EXPECTED_SPEED 临时改成一个不可能的值,例如 9999Mb/s,确认它会变成 down;测试完马上改回来。
12. 安全与维护建议
第一,不要把 Push token、真实内网地址、真实主机名写进公开文章或仓库。脚本可以放模板,真实值放环境文件,并限制文件权限:
chmod 600 /etc/default/lan-speed-checker
第二,LVM HTTP 服务尽量只允许 Uptime Kuma 访问。它虽然只读,但没有必要暴露到公网。
第三,阈值不要设得太贴边。local-lvm 到 99% 才报警通常已经晚了。家庭和小团队环境可以从 85% 或 90% 开始,根据容量增长速度调整。
第四,网口速率要按实际网络设计设置。如果你的 NAS 是 2.5G,期望值就应该是 2500Mb/s;如果某台软路由只有百兆管理口,不要硬套千兆规则。
第五,告警消息要写清楚。down 本身不够,actual=100Mb/s expected=1000Mb/s 才能让你第一眼知道发生了什么。
13. 告警之后应该怎么排查
监控的价值不只是把红点亮出来,更重要的是把排查顺序固定下来。否则告警来了之后,仍然可能从应用日志、数据库日志、代理日志一路绕远。我的建议是把这两类告警都当成“基础设施优先”的信号:先确认底层状态,再决定是否继续往上查。
13.1 local-lvm 告警后的排查顺序
local-lvm 告警后,不要马上删除文件,也不要直接扩容。先确认到底是数据区高,还是元数据区高。
lvs -o lv_name,vg_name,lv_size,data_percent,metadata_percent,lv_attr,pool_lv
pvesm status
如果 Data% 高,通常说明 VM/CT 磁盘实际写入量接近 thin pool 的物理容量。这个时候要看最近是否有:
- 新建或迁移了大磁盘虚拟机。
- 某台虚拟机内部日志、缓存、数据库、对象存储暴涨。
- 快照长期没有清理。
- 备份或临时数据误写入了虚拟磁盘。
- thin provisioning 过度承诺,多个虚拟磁盘同时增长。
如果 Meta% 高,问题更偏向 thin pool 元数据压力。大量快照、大量小块变更、频繁创建删除卷,都可能让元数据增长。此时只看 VM 内部剩余空间没有意义,因为元数据属于宿主机 LVM thin pool 自己的管理结构。
排查时可以先列出 VM 和 CT 的磁盘,再结合近期变更判断:
qm list
pct list
pvesm list local-lvm
如果你确实要清理空间,优先从业务上确认哪些虚拟机内部数据可以删除,哪些快照可以合并或移除。不要直接在宿主机上手工删除 LVM 设备文件。Proxmox 管理的卷应尽量通过 Proxmox 命令或 Web UI 操作,避免让 PVE 的配置状态和底层存储状态不一致。
如果要扩容,也要先确认底层 VG 是否还有空闲空间:
vgs
lvs
有空闲空间时,可以评估扩展 thin pool;没有空闲空间时,就要考虑迁移虚拟磁盘、增加物理盘、调整存储布局或清理无用卷。监控本身不替你做这个决定,它只负责让你在“快满但还没炸”的阶段知道问题。
13.2 网口速率告警后的排查顺序
网口速率告警通常比磁盘更直观,但也容易被误判。看到 actual=100Mb/s expected=1000Mb/s 时,不要只盯着 PVE。链路协商是两端共同决定的,任何一端端口、线材、水晶头、模块、驱动、电源管理策略都有可能影响结果。
建议按这个顺序查:
- 在 PVE 上执行
ethtool <INTERFACE>,确认告警里的速率不是脚本误读。 - 查看交换机或路由器对应端口的协商速率。
- 重新插拔网线,观察速率是否恢复。
- 更换一根确认质量正常的网线。
- 换交换机端口,排除单个端口问题。
- 检查是否开启了节能以太网、绿色以太网或自动省电功能。
- 查看内核日志里是否有网卡 link up/link down 抖动。
常用命令:
ethtool <INTERFACE>
dmesg -T | grep -Ei 'link is|renamed|eth|enp|speed'
journalctl -k --since '1 hour ago' | grep -Ei 'link|speed|duplex'
如果速率偶尔掉到百兆又恢复,重点怀疑线材、接头、交换机端口或电磁干扰。如果每次重启后都异常,重点看驱动、系统配置、交换机固定速率设置。如果只有大流量后异常,可能还要看网卡温度、供电、模块兼容性或交换机稳定性。
这里有个实际经验:不要只用测速软件判断链路是否恢复。先看 ethtool 的协商速率,再做传输测试。因为测速慢可能还有磁盘、CPU、SMB/NFS 协议、加密、远端写入性能等因素;而 Speed 是链路层结果,能先把问题范围缩小。
13.3 误报怎么处理
任何监控都会遇到误报。关键不是追求零误报,而是让误报可解释、可收敛。
local-lvm 误报常见原因有:
- PVE 正在重启,HTTP 服务短暂不可达。
jq或lvs路径不对,脚本在 cron/systemd 环境下找不到命令。- Uptime Kuma 到 PVE 的网络路径抖动。
- 阈值设得太低,正常波动也触发告警。
- thin pool 名称或输出字段和脚本假设不一致。
解决方式是先看脚本本地输出,再看 HTTP 服务日志,最后看 Uptime Kuma 的检查详情。不要只在 Uptime Kuma 页面上猜。
网口速率误报常见原因有:
- 监控接口写错,检查到了管理口或未接线接口。
- 机器实际是 2.5G,但期望值仍写成
1000Mb/s。 - 某些驱动在 link down 时返回
Unknown!,脚本按 down 处理,这是合理的,但消息需要写清楚。 - Push URL token 复制错,导致 Uptime Kuma 收不到心跳。
- cron 环境变量不完整,脚本没有加载到真实配置。
所以脚本里最好把实际接口名、实际速率、期望速率都写进消息。告警消息越具体,误报处理越快。
13.4 多台 PVE 怎么统一维护
如果只有一台 PVE,手工部署脚本就够了。多台 PVE 或多台 NAS/软路由时,就要考虑一致性。最简单的做法不是马上引入复杂平台,而是先把脚本模板固定下来:
lvm_check.sh保持一致,只通过环境变量调整阈值。lvm_http_server.py保持一致,只开放固定端口和路径。lan_speed_checker.sh保持一致,每台机器只改INTERFACE、EXPECTED_SPEED、PUSH_URL。- Uptime Kuma 监控命名保持统一,例如
pve-a local-lvm、pve-a link speed。 - 所有真实 Push URL 只保存在对应机器本地,不写进公共仓库。
这样以后新增机器时,只需要复制模板、改环境文件、在 Uptime Kuma 新建监控项。命名统一之后,告警消息也更容易看懂。
如果你已经使用 Ansible、SaltStack 或其他配置管理工具,可以把这三个脚本、两个 systemd 单元和一个环境文件纳入配置管理。注意 Push token 每台机器不同,最好作为受保护变量注入,不要硬编码到模板里。
13.5 阈值应该怎么定
磁盘阈值没有绝对标准。小容量机器和大容量机器的 90% 不是一个概念:100G 的 10% 只剩 10G,4T 的 10% 还剩 400G。更合理的做法是结合“百分比”和“增长速度”理解。
如果是小容量系统盘承载的 local-lvm,可以设得保守一些,例如 80% 到 85%。因为剩余空间不多,几个日志暴涨、一次备份误写入、一个快照忘删,就可能迅速耗尽。对于容量较大、增长规律稳定的存储池,可以先设 90%,再观察一段时间。
网口速率阈值则应该按设计值定,而不是按“能用”定。千兆链路掉到百兆,服务仍然能访问,但备份窗口、同步任务和远程桌面体验都会明显变差。2.5G 链路掉到千兆也是同理。如果你的设计目标是 2.5G,就应该按 2500Mb/s 监控,而不是因为千兆也能用就不告警。
13.6 为什么不直接改 Uptime Kuma 源码
这种需求很容易让人产生一个冲动:既然 Uptime Kuma 没有内置 local-lvm 和网口速率监控,那就给它加一个监控类型。技术上当然可以,但我不建议为了这类小众指标直接改源码。
原因很现实。第一,Uptime Kuma 升级频率不低,私有改动会让后续升级变得麻烦。第二,local-lvm、ZFS、普通目录、Ceph、iSCSI、不同网卡速率、不同系统命令,这些组合一旦做成通用功能,就会迅速膨胀。第三,监控项真正需要的只是一个二值结果和一段可读消息,没必要把所有环境差异都塞进 Uptime Kuma。
把复杂判断放在被监控机器本地,Uptime Kuma 只接收结果,是更稳的边界。PVE 自己最清楚 LVM 和网卡状态;Uptime Kuma 最擅长展示状态、维持心跳、发送通知。两边各做擅长的事,脚本也更容易被你自己理解、审计和替换。
这也是本文没有追求“平台化”的原因。家庭服务器和小团队系统最怕的是维护成本超过问题本身。一个几十行脚本、一个 systemd 服务、一个 Uptime Kuma 监控项,已经能解决 80% 的实际风险。等到你真的需要历史趋势、容量预测、跨主机聚合和复杂查询时,再引入 Prometheus、VictoriaMetrics、Grafana 或专门的日志指标系统也不迟。
13.7 我会怎样给告警命名
告警命名看似小事,但机器多了以后很重要。建议名称里包含三部分:主机角色、指标对象、期望状态。例如:
pve-main local-lvm thin pool
pve-main uplink speed 1000M
nas-a uplink speed 2500M
router-a wan-port speed 1000M
不要只命名为 disk、network、PVE check。真正收到通知时,你可能在外面、手机屏幕很小、没有登录后台的条件。标题越具体,你越容易判断是否需要立刻处理。对于网口速率告警,消息里再带上 actual 和 expected,基本就能在通知层面完成第一轮判断。
14. 参考资料
- Proxmox VE LVM-thin storage 文档:
https://pve.proxmox.com/pve-docs/pve-storage-lvmthin-plain.html - LVM thin provisioning 手册:
https://man7.org/linux/man-pages/man7/lvmthin.7.html - Uptime Kuma Push endpoint 说明:
https://github.com/louislam/uptime-kuma/wiki/Internal-API
15. 总结
这套方案的价值不在于脚本多复杂,而在于把两个“低频但高伤害”的问题提前纳入统一监控。
local-lvm 满了,影响的是虚拟机、容器、快照、备份和写入稳定性;网口掉速,影响的是 NAS、软路由、备份、同步和所有大文件传输。它们都不一定让服务立刻宕机,却会制造大量看似随机的应用层问题。
把 LVM thin pool 的 Data%、Meta% 和网口协商速率接到 Uptime Kuma 后,排障路径会短很多:看到告警,先处理基础设施;没有告警,再继续查应用。对家庭服务器和小团队系统来说,这已经能挡住不少“明明昨天还好好的”事故。