别再迷信 Agent 框架:12-Factor Agents 才是 AI 时代的工程底线
先说结论
12-Factor Agents不是一个让你安装后直接开箱即用的 Agent 框架,也不是某种 Codex / Claude / Cursor 里的 Skill。它更像 AI 时代写 Agent 的工程原则清单:当你发现“把大模型、工具列表和一个 while loop 拼起来”只能做到 70% 到 80% 可用,却迟迟过不了生产质量线时,这套原则会提醒你把提示词、上下文、工具调用、状态、人类审批、错误压缩和控制流重新收回到软件工程手里。我最喜欢它的一点,是它没有把 Agent 神化。相反,它反复强调:可靠的 Agent 并不是“让模型自由发挥”,而是把 LLM 放在一个可观察、可恢复、可审计、可中断、可复现的系统里。真正值得学习的不是某个框架 API,而是这背后的工程姿势。
本文所有示例都使用公开项目、公开链接和占位符,不包含真实服务器地址、账号、Token、业务配置或任何内网信息。文中配图来自 HumanLayer 开源项目 12-factor-agents 的官方仓库,内容按其 CC BY-SA 4.0 授权引用;代码授权信息以原仓库为准。
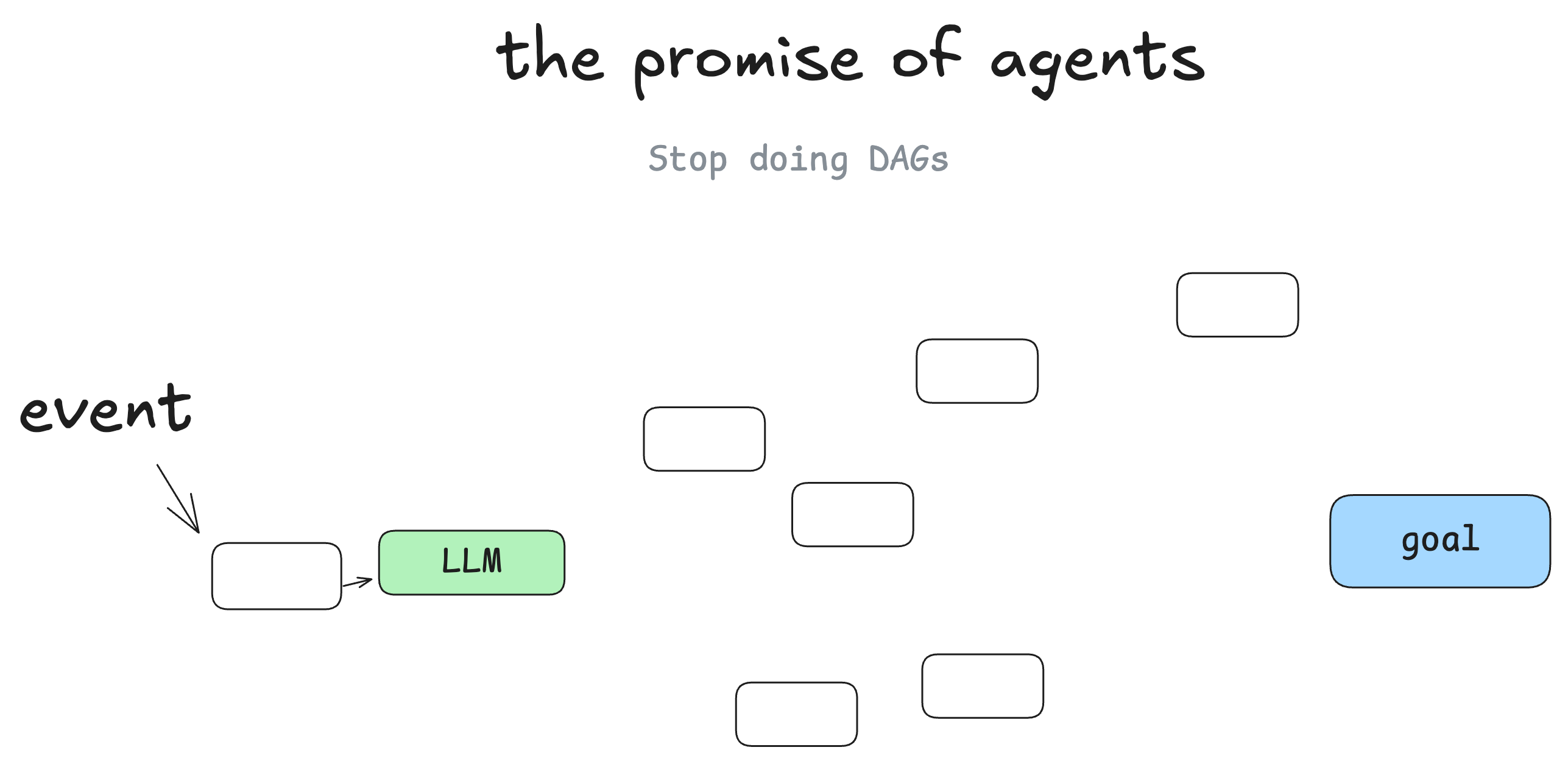
图 1:12-Factor Agents 用图解释了一个关键转变:我们不是彻底扔掉软件结构,而是把一部分路径选择交给 LLM。图片来源:humanlayer/12-factor-agents。
1. 为什么现在需要重新讨论 Agent 原则
过去一年里,很多人做 Agent 的第一反应是找框架:LangChain、LangGraph、CrewAI、AutoGen、各种 RAG 框架、各种工具调用封装、各种“多智能体平台”。这些东西当然有价值,尤其适合快速 Demo、快速验证、快速把工具接起来。但真正把 Agent 放到生产场景时,问题往往不是“有没有框架”,而是“系统是否可控”。
我见过很多 Agent 项目卡在同一个位置:Demo 很顺,录视频很好看,内部试用也能跑通;一到真实用户、真实数据、真实失败、真实权限边界,就开始变得难以解释。模型有时会漏掉上下文,有时会把工具参数拼错,有时会在错误信息里越绕越远,有时会把本该由业务系统决定的状态藏在对话历史里,有时还会在需要人类审批的地方假装自己能继续。
这个阶段最危险的错觉,是继续加模型、加工具、加更长的 prompt、加更多 retry。短期看似能提升成功率,长期会把系统变成一团很难维护的胶水。你以为自己在做智能体,实际得到的是一个“黑箱里的流程引擎”:状态散落在上下文窗口里,控制流散落在 prompt 里,错误处理散落在日志里,人工确认散落在聊天记录里。
12-Factor Agents 的价值就在这里。它把问题从“选哪个框架”拉回到“怎样设计 LLM-powered software”。项目 README 里说得很直接:好的 Agent 不是一个简单的“给 prompt、给工具、循环直到完成”的模式,而是主要由软件构成,只在合适的点把 LLM 放进去。这个判断非常重要,因为它把 Agent 从玄学拉回工程。
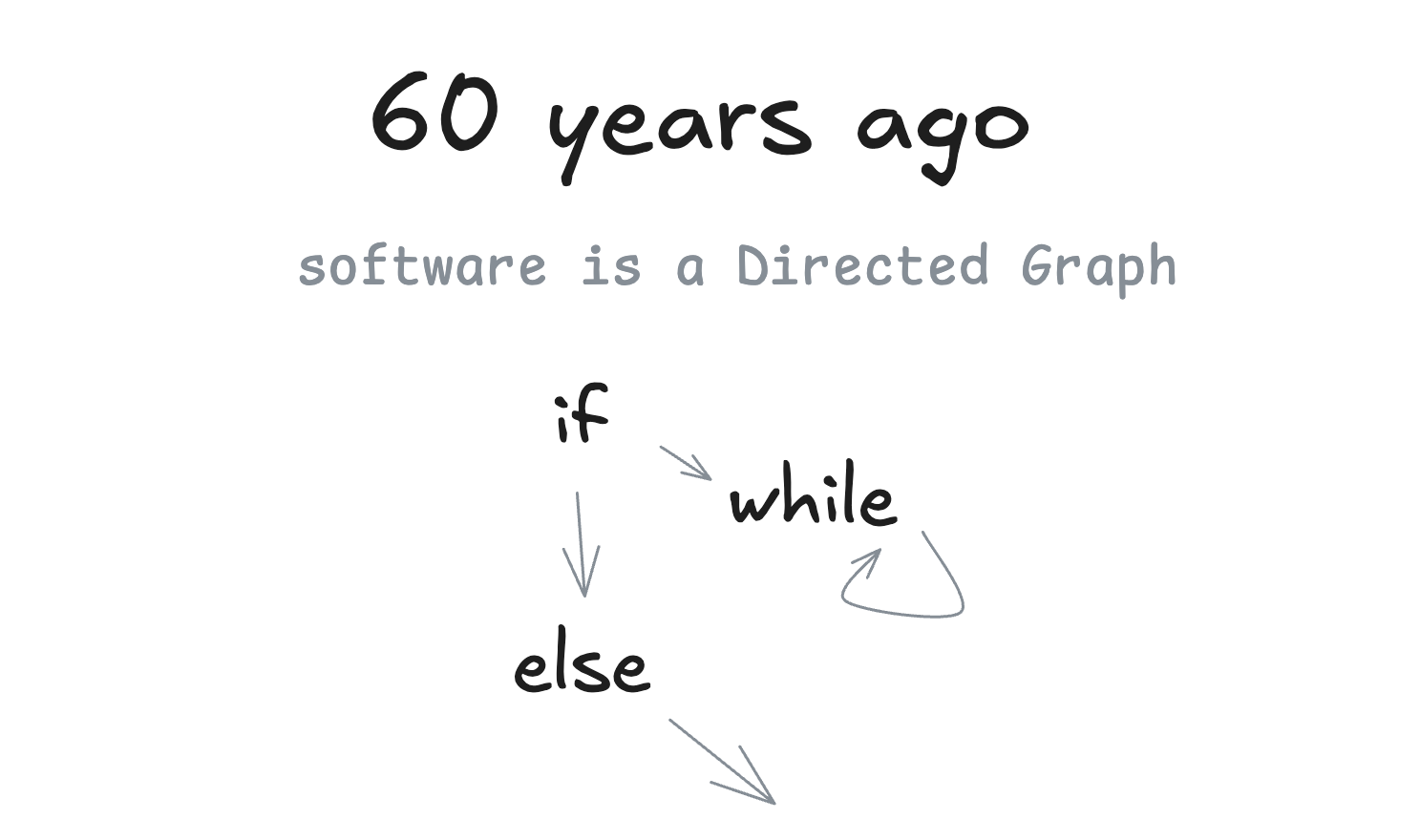
图 2:传统软件也可以看作有向图。理解这一点后,就不会把 Agent 误解成“没有流程”。图片来源:humanlayer/12-factor-agents。
2. 问题表现:为什么很多 Agent 只能到 80%
如果你做过面向真实用户的 Agent,很可能遇到过这些表现。
第一,上下文越来越长,但结果没有越来越稳。一开始你把用户需求、系统说明、工具描述、历史记录都塞进 prompt,感觉模型知道得更多了。很快你会发现,长上下文并不等于好上下文。过期信息、重复信息、错误尝试、无关日志、临时判断一起进入窗口后,模型反而更容易分心。它不是没有能力,而是输入被污染了。
第二,工具调用看似标准,实际语义不清。很多框架会把 tool call 包装得很漂亮:函数名、参数 schema、返回值都齐了。但在业务上,“调用工具”不是目的,工具输出背后代表的业务状态才是目的。比如“发送审批请求”“创建工单”“重试部署”“向用户确认付款信息”,这些不是普通函数调用,而是带状态、权限、审计和回滚语义的业务动作。如果只把它们当作 LLM 的工具列表,系统很容易失控。
第三,流程控制被 prompt 偷偷接管。一个常见写法是:让模型判断下一步应该做什么,然后把结果丢给工具执行,再把工具结果放回上下文,继续下一轮。这种 loop 很容易写出来,也很容易演示。但只要任务稍微复杂,就会出现两个问题:人很难知道模型为什么选这条路径;系统也很难在关键节点插入确定性的保护逻辑。
第四,错误信息越堆越多,模型越修越偏。当工具失败时,很多系统直接把完整错误、完整 stack trace、完整 stdout/stderr 塞回上下文。模型看到一大坨日志后,有时会抓错重点:它可能被底层库的噪声误导,忽略真正的业务错误;也可能在同一个失败路径里重复尝试,把上下文变成失败记录垃圾场。
第五,人类审批不是一等公民。真实 Agent 经常要问人:这个操作能不能执行?这个账单能不能发?这个客户能不能联系?这条命令会不会影响生产?如果系统把“问人”当成聊天补丁,而不是一个可追踪的工具调用,就会出现审批记录不完整、恢复困难、责任边界不清的问题。
这些表现的共同根因是:我们把太多原本属于软件工程的东西外包给了模型和框架。模型应该负责语言理解、候选决策、结构化提议、少量模糊判断;但状态管理、权限边界、控制流、错误归纳、审计记录、用户触达,不应该消失在上下文窗口里。
3. 12-Factor Agents 到底是什么
12-Factor Agents 是 HumanLayer 发起的开源项目,灵感显然来自经典的 12-Factor App。后者曾经帮助很多团队用一组原则理解云原生应用:配置、依赖、日志、进程、端口绑定、环境一致性等。12-Factor Agents 做的是类似的事情,只不过对象变成了 LLM 应用和 Agent 系统。
截至我写作时,项目在 GitHub 上已经有两万多 Star,说明它击中了很多工程团队的共同焦虑:大家都在做 Agent,但并不想被某个框架完全绑死;大家都想让模型参与工作流,但又不愿意把业务系统的可靠性押在黑箱上。
它列出的 12 个因素分别是:
- Natural Language to Tool Calls:把自然语言转成可执行的工具调用。
- Own your prompts:把 prompt 当成你自己的代码和资产。
- Own your context window:主动管理上下文窗口,而不是把所有历史都塞进去。
- Tools are just structured outputs:工具调用本质上是结构化输出,不要被框架魔法迷惑。
- Unify execution state and business state:执行状态和业务状态要统一。
- Launch / Pause / Resume with simple APIs:用简单 API 支持启动、暂停、恢复。
- Contact humans with tool calls:联系和等待人类,也应该是工具调用。
- Own your control flow:控制流要掌握在自己的代码里。
- Compact errors into context window:把错误压缩成模型真正需要的上下文。
- Small, Focused Agents:Agent 要小而聚焦。
- Trigger from anywhere, meet users where they are:从用户所在的地方触发和交互。
- Make your agent a stateless reducer:把 Agent 设计成基于状态和事件的无状态 reducer。
这 12 条不是“必须照抄的架构模板”,更像一组检查项。你每做一个 Agent,都可以问自己:prompt 是否可版本化?上下文是否可构造?工具输出是否结构化?状态是否可恢复?人类审批是否可追踪?错误是否经过压缩?控制流是否被代码掌握?Agent 是否足够小?
如果答案大多是否定的,那么你可能不是在做工程系统,而是在做一个运气不错的聊天脚本。
4. 我认为最重要的不是 12 条,而是 4 个转向
完整 12 条很有价值,但如果把它们压缩成更容易记住的工程转向,我会归纳成四类。
4.1 从“神奇 prompt”转向“可维护 prompt”
很多团队一开始会把 prompt 当配置文本,甚至当临时说明。谁调通了就贴到环境变量里,谁觉得效果不好就直接改几句。这样做在 Demo 期没问题,进入多人协作后很快失控。
Own your prompts 的核心不是“把 prompt 写得更长”,而是“承认 prompt 是代码”。既然是代码,就应该有版本、评审、测试、回滚、命名、结构和所有权。你需要知道每个 prompt 的目标是什么,输入变量是什么,输出格式是什么,边界条件是什么,为什么这么写,改动后会影响哪些任务。
更现实一点说,prompt 不应该只是模型消息里的大字符串。它应该靠近业务代码,能被测试,能被比较,能和 schema、示例、工具描述一起演进。否则某天线上 Agent 行为变化时,你很难判断是模型更新、上下文变化、工具返回变化,还是某个人改了 prompt 的一句话。
4.2 从“上下文堆叠”转向“上下文构造”
Own your context window 是整套原则里最接近当下热点 Context Engineering 的部分。很多人以为长上下文模型解决了一切,实际上长窗口只是给了你更大的房间,不代表房间会自己变整洁。
好的上下文应该是被构造出来的。它至少包含几类信息:当前用户意图、必要业务事实、可用工具和约束、最近关键事件、可恢复状态、失败摘要、需要模型决策的开放问题。它不应该默认包含所有聊天记录、所有日志、所有工具返回、所有无关文档。
这也是为什么 RAG、memory、scratchpad、conversation history 不能混为一谈。RAG 是从外部知识库取资料,memory 是长期偏好或事实,scratchpad 是过程推理痕迹,conversation history 是交互记录。它们进入上下文前都应该被筛选、排序和压缩。

图 3:12-Factor Agents 把“拥有上下文窗口”作为核心原则之一。图片来源:humanlayer/12-factor-agents。
4.3 从“工具就是函数”转向“工具是结构化协议”
工具调用看似是函数调用,但在 Agent 系统里更像一份协议。模型不是直接执行世界,它输出一个结构化意图;你的代码验证这个意图,执行确定性动作,再把结果以受控格式反馈回去。
这意味着工具 schema 不能只追求“模型容易填”。它还要表达业务边界。哪些字段必填?哪些字段需要审批?哪些字段只能来自系统而不能来自用户?哪些操作具备幂等性?哪些返回值应该进入上下文?哪些错误应该暴露给模型?这些都应该在工具层明确。
我更喜欢把 tool call 理解成“模型给软件系统写的一张申请单”。申请单可以被接受、拒绝、补充、排队、审计、重试,也可以要求人工确认。模型负责把自然语言转成结构化申请;软件负责决定是否执行。
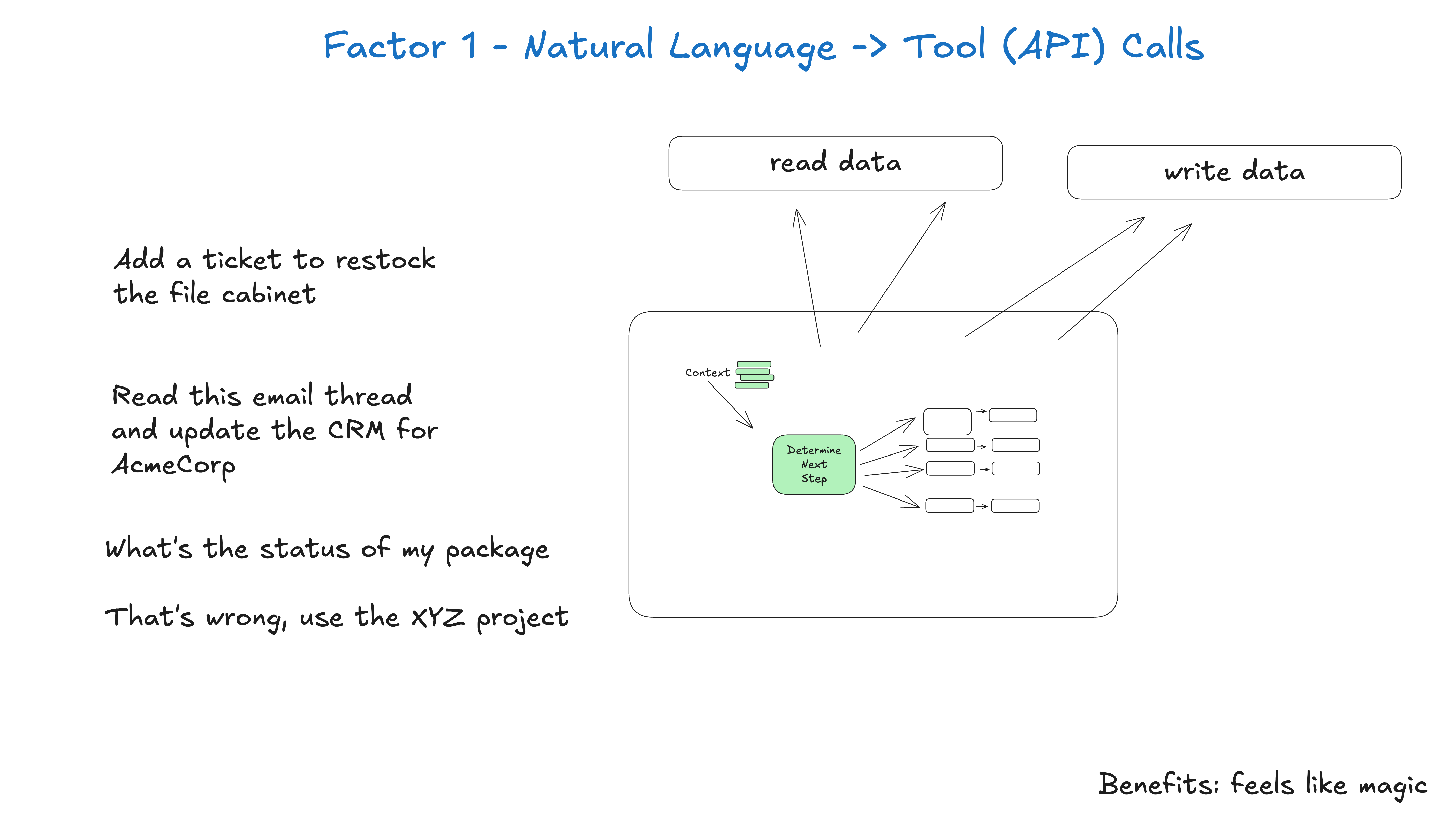
图 4:从自然语言到工具调用,不等于把执行权完全交给模型。图片来源:humanlayer/12-factor-agents。
4.4 从“会话状态”转向“业务状态”
很多 Agent 难以恢复,是因为它把状态放错了地方。比如一次部署 Agent 的流程:用户说要发布,模型选择分支,检查 CI,生成计划,等待审批,执行部署,观察指标,通知结果。这里的状态不应该只存在于聊天历史里。它应该在业务系统中有明确记录:当前阶段、输入、输出、审批人、失败原因、下一步动作、是否可重试。
Unify execution state and business state 正是在讲这个问题。执行状态不是框架内部的临时变量,业务状态也不是数据库里另一套孤立字段。可靠的 Agent 应该让两者统一:你从数据库或事件流恢复出来的状态,应该足以继续执行;你在执行过程中产生的状态,也应该能被业务系统、审计系统和用户界面理解。
这一点会直接影响系统可运维性。如果 Agent 进程挂了,能不能继续?如果用户隔天回复审批,能不能恢复?如果任务失败三次,能不能知道卡在哪一步?如果模型升级后行为变化,能不能用旧事件重放?这些问题都不是 prompt 能解决的,它们是状态设计问题。
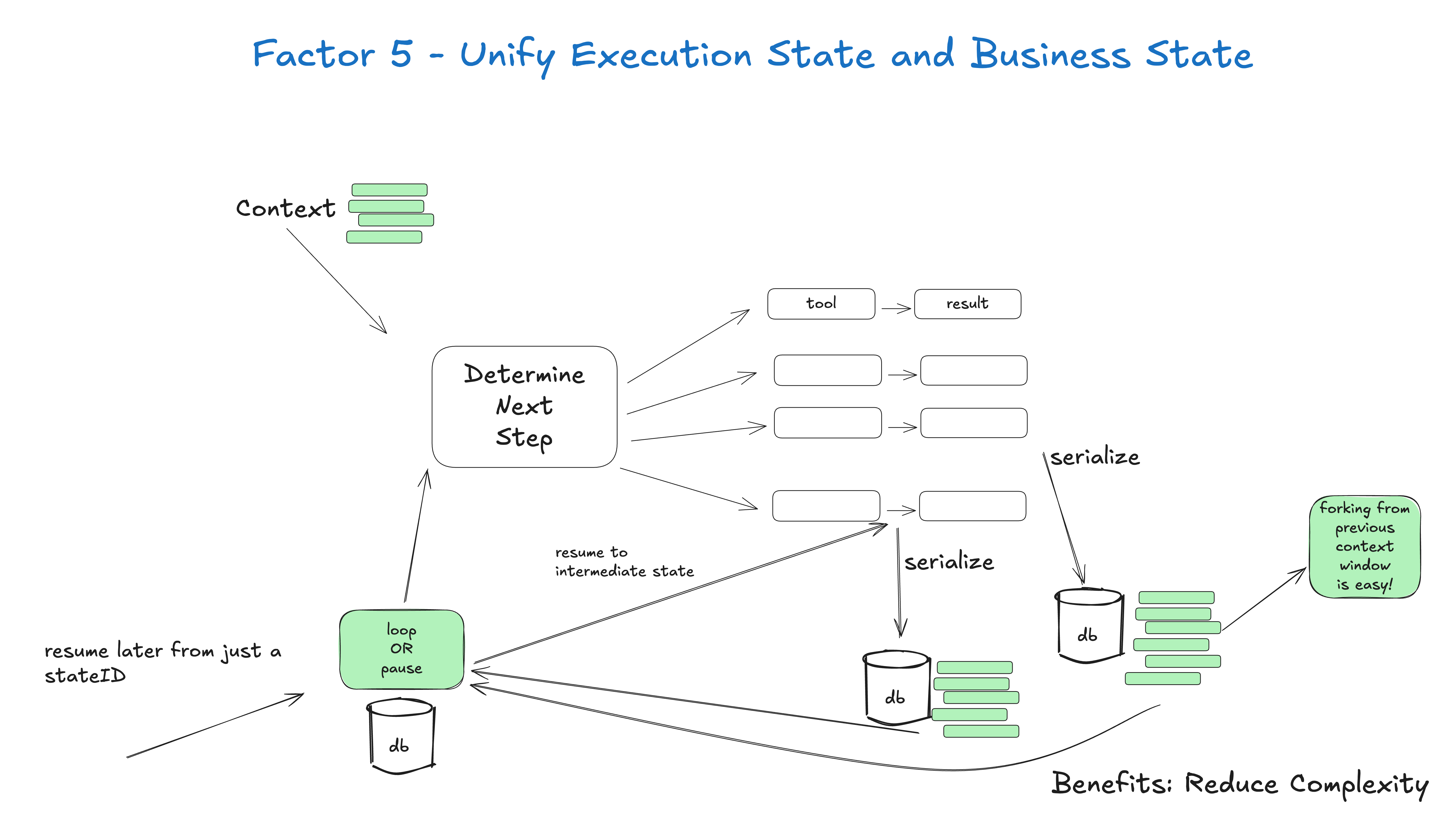
图 5:把执行状态和业务状态统一,是 Agent 可靠性的基础。图片来源:humanlayer/12-factor-agents。
5. 问题根因:我们把不确定性放大了
LLM 的价值来自不确定性。它能理解自然语言,能处理模糊输入,能在不完整信息里给出候选方案,能把人类意图翻译成机器可执行的结构。这正是它强的地方。
但工程系统的可靠性来自确定性。权限校验应该确定,账单生成应该确定,部署步骤应该确定,幂等键应该确定,审计记录应该确定,失败恢复应该确定。Agent 系统最难的地方,不是选择“全确定”或“全智能”,而是把不确定性放在正确的位置。
很多失败的 Agent 架构,是把不确定性一路放大:用户输入不确定,prompt 不确定,上下文不确定,工具选择不确定,状态记录不确定,错误处理不确定,恢复路径也不确定。最后系统当然会变成“有时很聪明,有时很离谱”。
12-Factor Agents 的本质,是把这种不确定性重新围起来。让模型负责它擅长的部分:理解、分类、提议、生成结构化候选、在开放空间里搜索方案。让代码负责它必须负责的部分:状态、权限、控制流、校验、执行、审计、恢复。
这也是为什么我不把它看作一个“教程项目”,而更愿意把它看作 Agent 时代的工程底线。它提醒我们:不要因为模型会说话,就忘了系统仍然要像软件一样被设计、测试、部署和维护。
6. 如何落地:给现有 Agent 做一次 12-Factor 体检
如果你已经有一个 Agent,不需要马上推倒重来。可以先做一次体检。
6.1 检查 prompt 是否可管理
先找出系统里所有 prompt。它们是否散落在代码、数据库、配置、控制台和临时变量里?是否有版本?是否有人知道每个 prompt 的责任?是否有输出 schema?是否能用固定样例做回归测试?
如果答案不清楚,第一步不是重构框架,而是把 prompt 收拢到代码仓库或清晰的配置层里。给每个 prompt 起名字,写明输入输出,保留修改历史,配几个代表性测试样例。这样做并不炫,但会立刻降低不可解释性。
6.2 检查上下文是否主动构造
拿一条真实任务,打印每轮发给模型的上下文。你会很快看到问题:是否包含过多历史?是否有重复工具结果?是否混入了无关日志?是否缺少当前任务的关键业务事实?是否把旧失败当成新事实?
然后把上下文拆成几个来源:系统规则、用户当前输入、业务状态、检索资料、短期历史、错误摘要。每个来源都要有进入窗口的条件和最大长度。不要让“全部 append”成为默认策略。
6.3 检查工具是否有业务语义
列出所有工具,问三个问题:这个工具是否幂等?失败后能否安全重试?执行前是否需要权限或人类审批?如果某个工具会修改外部世界,却没有幂等键、审批记录和清晰错误分类,它就不应该直接暴露给模型自由调用。
工具返回也要控制。返回给模型的不是越完整越好,而是越有决策价值越好。对模型来说,“HTTP 500 + 800 行栈”通常不如“支付网关超时,订单未确认扣款,可使用同一幂等键重试,最多再试 2 次”。
6.4 检查控制流是否在代码里
如果你的主循环是“模型决定下一步,工具执行,结果 append,继续”,那就要小心。不是说这种 loop 一定不能用,而是关键业务路径最好由代码控制。
例如部署 Agent 可以允许模型生成候选计划,但“检查 CI、等待审批、执行部署、观察指标、回滚判断”这些阶段最好是明确状态机。模型可以在阶段内部做判断,不能随意跳过阶段。这样才能保证系统有边界。
6.5 检查人类是否是一等参与者
如果 Agent 需要问人,就把“问人”设计成工具调用和状态转换,而不是随手发一条消息。请求内容、审批对象、超时时间、可选项、审批结果、恢复位置都应该被记录。人类回复后,系统应该能从状态中继续,而不是依赖某个在线进程还记得前文。
6.6 检查 Agent 是否足够小
一个 Agent 同时负责销售、客服、账单、部署、数据分析和通知,听起来强大,实际很难稳定。Small, Focused Agents 不是说每个 Agent 都要很弱,而是说边界要清楚。一个小 Agent 更容易测试,更容易收敛上下文,更容易做权限控制,也更容易解释失败。
7. 一个更实际的 Agent 架构草图
如果让我基于 12-Factor Agents 设计一个真实可落地的 Agent,我会把它拆成几层。
第一层是 入口层:聊天窗口、网页按钮、Webhook、定时任务、邮件、工单系统都可以触发任务,但它们只负责生成标准事件,不直接驱动业务逻辑。
第二层是 状态层:每个任务都有一条明确的业务记录,包含任务类型、阶段、输入、输出、审批、错误摘要、重试次数和下一步动作。状态存在数据库或事件流里,不存在模型记忆里。
第三层是 上下文构造层:每次调用模型前,系统从状态、用户输入、必要文档、最近关键事件和错误摘要里构造上下文。它不是聊天历史的简单拼接,而是一个可测试的函数。
第四层是 LLM 决策层:模型只输出结构化候选,例如下一步工具调用、字段提取结果、风险分类、用户回复草稿、错误归因候选。它不直接改数据库,也不直接执行外部动作。
第五层是 工具执行层:代码验证模型输出,检查权限、幂等、审批和业务约束,然后执行动作。执行结果被压缩成状态更新和模型可读摘要。
第六层是 人类协作层:需要人类判断时,系统发出可追踪请求,暂停任务,等待回复,再从状态恢复。
第七层是 观测与回放层:每次模型输入、结构化输出、工具执行、状态变化、审批和错误摘要都有记录。线上问题出现后,可以回放事件,定位是上下文构造问题、模型判断问题、工具执行问题,还是业务状态问题。
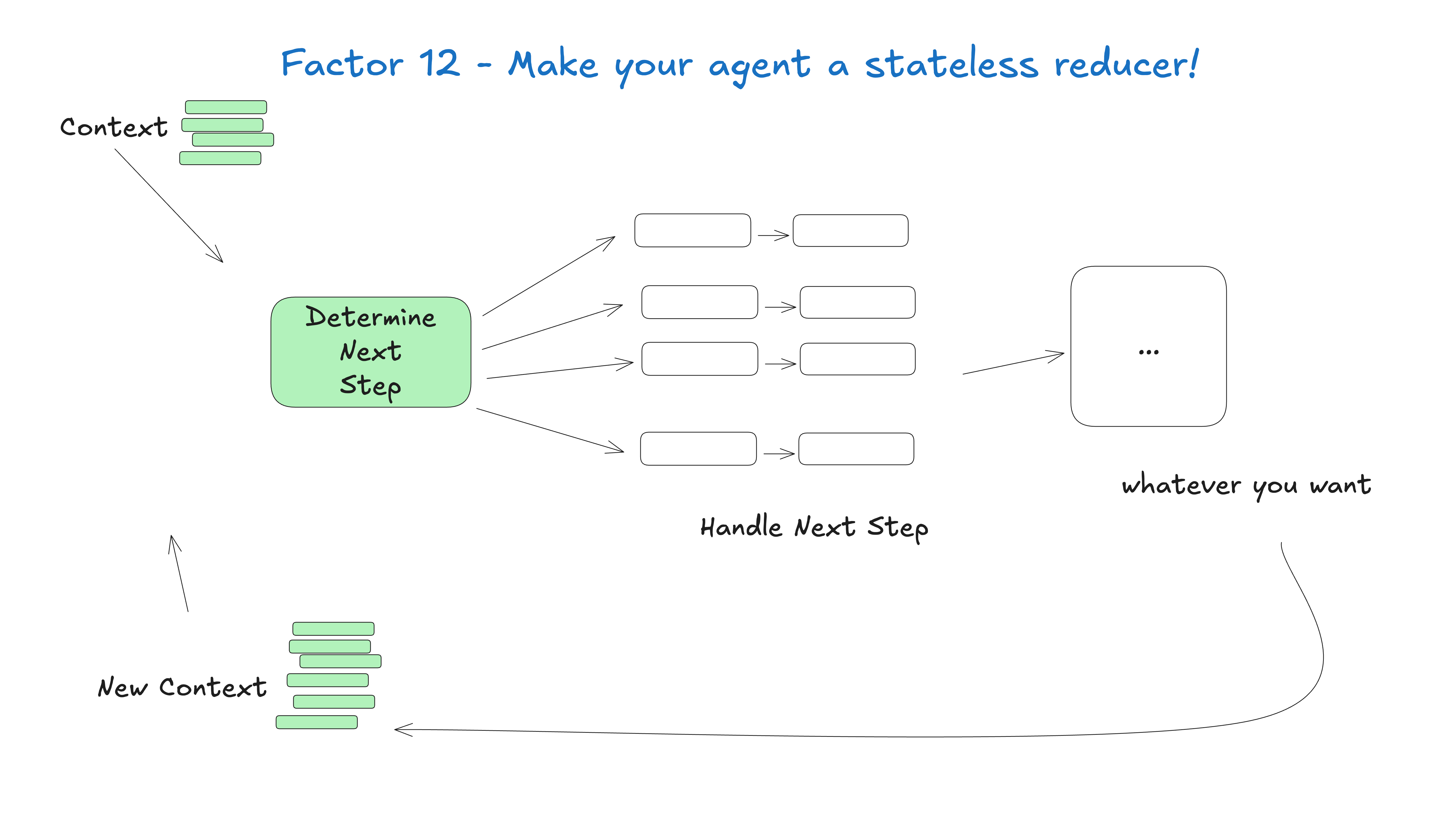
图 6:把 Agent 看成 stateless reducer 后,恢复、回放、测试都会简单很多。图片来源:humanlayer/12-factor-agents。
8. 它和 Skill、MCP、RAG、LangGraph 到底是什么关系
很多人容易把这些概念混在一起。我的理解是:
Skill 更像某个工具或 Agent 的能力包。它通常包含操作说明、约束、脚本、模板和工作流知识。Skill 可以帮助 Agent 更好地完成某类任务,但它不是 Agent 设计原则本身。
MCP 更像工具和上下文的开放协议。它解决的是模型应用如何连接外部资源、工具、数据和服务。MCP 很重要,但它主要回答“怎么接”,不直接回答“Agent 的状态和控制流应该怎么设计”。
RAG 解决的是外部知识检索问题。它能让模型拿到资料,但不能自动保证任务状态、审批、工具幂等和错误恢复。
LangGraph 这类框架可以帮助你显式建图和管理状态。它可能是实现 12-Factor 思路的工具之一,但原则本身不依赖某个框架。
所以 12-Factor Agents 的位置更靠上。它不是某个可安装插件,而是一套判断标准。你可以用 LangGraph 实现,也可以用普通后端代码实现;可以接 MCP,也可以接自定义工具;可以用 RAG,也可以不用。关键是不要把工具当原则,也不要把框架当架构。
9. Q&A
Q1:既然强调控制流在代码里,那 Agent 还智能吗?
智能不等于失控。一个可靠 Agent 应该在正确的地方智能:理解需求、生成候选、做语义判断、提出计划、归纳错误、写解释、处理模糊表达。控制流在代码里,只是说明关键业务路径不应该完全靠模型自由游走。
Q2:是不是不用框架最好?
不是。框架可以节省大量基础工作,比如消息结构、工具绑定、状态图、可视化、持久化和重试。问题不在“用不用框架”,而在你是否知道框架帮你做了什么、没帮你做什么。一旦生产问题出现,你必须能打开黑箱。
Q3:长上下文模型会不会让这些原则过时?
不会。更长的窗口让你能放更多信息,但不会自动帮你判断哪些信息重要。上下文越长,越需要治理。否则你只是把垃圾桶做得更大。
Q4:Agent 要不要拆成很多小 Agent?
要看边界。为了拆而拆会增加协调成本;一个大 Agent 什么都管又会失控。比较好的判断是:能否独立描述职责、输入、输出、权限和失败处理。如果不能,就说明边界还不清楚。
Q5:普通个人项目需要这么严肃吗?
如果只是玩具项目,不需要。把模型接上几个工具跑起来就行。但只要它会修改文件、访问账号、花钱、发消息、部署服务、影响真实用户,就应该至少做基本的状态、审批、日志和错误压缩。
Q6:这套原则最值得先做哪三条?
我的建议是:先做 Own your prompts、Own your context window、Own your control flow。这三条能最快把系统从“聊天脚本”拉回“工程系统”。随后再补状态统一、人类审批和错误压缩。
10. 总结:Agent 时代真正稀缺的是工程纪律
现在的 AI 工具太容易让人产生错觉:只要模型够强、上下文够长、工具够多,系统就会自然变可靠。但真实情况往往相反。模型越强,越容易让 Demo 看起来像生产;工具越多,越容易让边界变模糊;上下文越长,越容易把状态管理偷懒成历史堆叠。
12-Factor Agents 值得读,不是因为它提供了某个神奇框架,而是因为它把注意力拉回了工程纪律:prompt 要拥有,上下文要拥有,工具输出要结构化,状态要统一,控制流要掌握,错误要压缩,人类要进入协议,Agent 要小而专注,最终系统要能像 reducer 一样被恢复、回放和测试。
如果你正在做 Agent,我建议不要把它当作“又一个开源项目收藏”。更好的用法是拿它做一次架构体检:把你的 Agent 逐条对照,看哪些原则已经具备,哪些原则只是靠运气,哪些原则完全缺席。真正的收益不是打满 12 个勾,而是知道自己的系统为什么还不可靠,以及下一步该从哪里开始变可靠。
AI 时代不会让软件工程消失。恰恰相反,越是把 LLM 放进真实业务,越需要工程纪律把不确定性关在合适的位置。12-Factor Agents 给出的不是终点答案,而是一份很清醒的出发清单。
参考资料与图片来源
- HumanLayer:
12-Factor Agents - Principles for building reliable LLM applications,https://github.com/humanlayer/12-factor-agents - 12-Factor Agents 官方内容目录,https://github.com/humanlayer/12-factor-agents/tree/main/content
- 12-Factor Agents 官方图片目录,https://github.com/humanlayer/12-factor-agents/tree/main/img
- 12-Factor App,https://12factor.net/
- Anthropic:
Building effective agents,https://www.anthropic.com/engineering/building-effective-agents - 本文引用图片均来自
humanlayer/12-factor-agents官方仓库,内容和图片按原项目声明的 CC BY-SA 4.0 授权引用;代码部分按原项目声明的 Apache 2.0 授权。