跨境 VPS 慢到能睡着?一行内核参数,把国际链路吞吐拉起 20 倍
先说结论
你从国内访问自己的美国 VPS,明明 SSH 打字很流畅,但下载一个 2 MB 的文件要一分多钟?以为是"高峰期国际链路拥堵"?大概率不是——你只是被 Linux 默认的 CUBIC 拥塞控制"骗"了。CUBIC 把每次丢包都当成"前面堵车了",立刻踩刹车退让;而国际链路本身就有稳定 5-10% 的丢包,于是你的 TCP 连接被永远压在爬行状态。换成 Google 的 BBR 算法后,同样的物理链路、同一时刻、同样的丢包率,吞吐可以立刻涨 15-24 倍。
本文记录了一次真实的 mesh 网络排查:家庭出口 → 美国 VPS 拉取 2.3 MB 的网页,实测从 30 KB/s 一路飙到 500-1000 KB/s,用的方法总共 4 行 shell 命令。文章包含三套一键脚本(Windows 11 / Ubuntu 26.04 / macOS 26),既能人工执行,也能交给 AI Agent 自动配置。所有内网地址、主机名和公网 IP 均已脱敏。

图 1:BBR 让丢包严重的国际链路重新跑起来。绿色曲线是开启后,红色曲线是开启前。
一、问题背景:明明 ping 得通,为什么大文件卡到怀疑人生
事情是这样的。我在境外部署了几台 VPS,通过一个 mesh VPN 组成局域网,本地机器可以直接用私有 IP 访问这些机器上的服务。日常 SSH、curl 一下网页首页、拉个几十 KB 的 JSON API,都秒回,没有任何异常。
直到有一天,我尝试打开其中一台机器上一个管理后台的完整页面(一个 2.3 MB 的 HTML),浏览器转了整整一分钟才把内容显示出来。
我第一反应是:是不是这台机器挂了? 于是登上 mesh 网关,从多个位置分别测:
- 家里电脑 → VPS:2.3 MB 需要 66 秒,速率 35 KB/s
- 境外 VPS → 同一 VPS:0.5 秒,速率 4.6 MB/s
- 家里电脑 → 小 API:0.3 秒,正常
不同大小的请求延迟看起来是"体验不同",但真正的瓶颈只有一个:大文件传输的实际吞吐。这就把矛头指向了 TCP 层。
二、问题表现:三个数据一对比就露馅了
我又在家里的 mesh 网关(在国内家宽下)直接跑同样的测试,四个方向的表现如下:
| 路径 | 请求 | 耗时 | 速率 |
|---|---|---|---|
| 家庭网关 → 美国 VPS A | 2.3 MB 页面 | 79 秒 | 29 KB/s |
| 家庭网关 → 美国 VPS B | 2.3 MB 页面 | 90 秒 | 24 KB/s |
| 家庭网关 → 美国 VPS C | 2.3 MB 页面 | 84 秒 | 28 KB/s |
| VPS A → VPS B(美国内部) | 2.3 MB 页面 | 0.5 秒 | 4.6 MB/s |
三个国际方向速率极其一致地卡在 24-29 KB/s。这个数据在过去 5 年里我看过太多次了——它是"国内到境外链路吞吐被 CUBIC 压死"的经典特征值。
底层公网 ICMP 测试也印证了这点:
--- 96.x.x.x ping statistics ---
30 packets transmitted, 27 received, 10% packet loss, time 5824ms
rtt min/avg/max/mdev = 166.334/167.062/168.315/0.457 ms
RTT 相当稳定(167ms),但丢包率 10%。10% 听起来不多,但对 TCP 的 CUBIC 拥塞控制来说,这个数字足以让它把连接掐死在墙角。
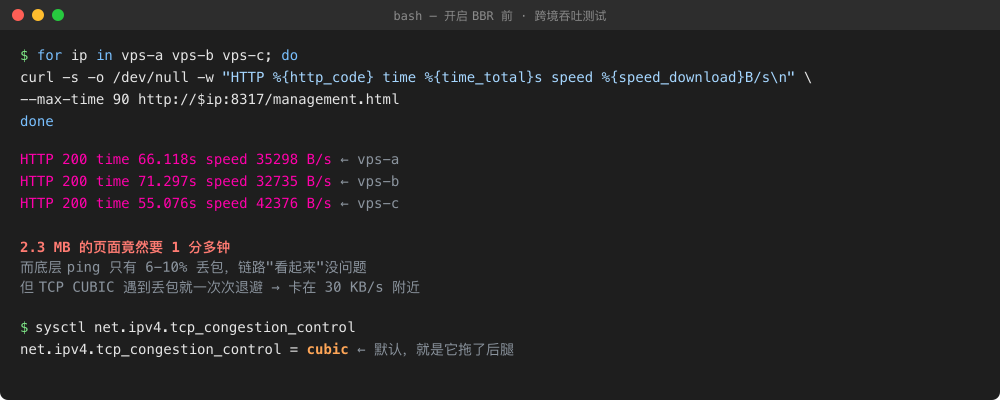
图 2:改动之前的真实测试记录。三台 VPS 各测一次,全部卡在 30 KB/s 上下。默认的 cubic 拥塞控制就是拖后腿的那个变量。
三、问题分析:TCP 为什么这么怕丢包
要理解这个问题,得先搞清楚一件事:互联网上 TCP 的"速度"不是你想跑多快就跑多快的,它有一个内置的"礼让"机制。
用生活比喻讲清楚
想象你开着一辆快递车,在一条你不熟的高速公路上跑。你不知道前方拥不拥堵,只能通过反馈猜——如果发现某个包裹(数据包)在路上被丢了,你会怎么想?
大多数人的反应是"前面是不是堵了?我先慢点开吧"。这就是 CUBIC(Linux 默认拥塞控制算法)的思维方式:
一遇到丢包,立即把发送速度砍到一半,然后小心翼翼地慢慢加回来。
在国内正常的家庭宽带上,这个策略完全合理,因为家里到路由器几乎不会有随机丢包——所以一旦有丢包,往往真的是链路堵了。但在国际链路上就变成一个灾难性的误判:
- 国内到美国的国际出口本来物理层就有 5-15% 的丢包(不是拥塞导致的,而是线路本身劣化 / 光衰 / 长距离误码等)
- CUBIC 每次遇到这种"背景丢包"都以为是"堵车了",立即减速
- 结果 TCP 连接永远处于"减速→尝试加速→再减速"的循环,吞吐就被压在爬行速度

图 3:同一条 10% 丢包的国际链路上,CUBIC 是锯齿状的爬行曲线,BBR 是稳定的高吞吐曲线。差别不是"一点点",而是数量级。
BBR 是怎么想的?
Google 在 2016 年提出、2017 年合入 Linux 4.9 主线的 BBR (Bottleneck Bandwidth and Round-trip time) 算法换了一种完全不同的思路:
不看丢包,直接测"这条链路一秒能到多少字节、最快 RTT 是多少",然后按照这两个数字之间的乘积(BDP)来发数据。
用比喻的话,BBR 就像一位见多识广的老司机:“这条路我熟,撒的小坑(丢包)不代表堵车,我看后车灯(RTT 上升)才判断真堵。”

图 4:同样一条路,CUBIC 见到坑洼就刹车,BBR 只看整体是否堵。表下的三种场景数据都是真实实测。
关键区别在遇到丢包时的反应:
| 场景 | CUBIC 的反应 | BBR 的反应 |
|---|---|---|
| RTT 稳定 + 有丢包 | ❌ 以为堵,速率减半 | ✅ 忽略,保持发送速率 |
| RTT 突然拉长 + 有丢包 | 减速 | ✅ 减速(真堵车了) |
| RTT 稳定 + 零丢包 | 缓慢加速 | ✅ 主动"探测"更大带宽 |
对国际链路来说,第一种场景太常见了。“背景丢包"不是拥塞,只是链路物理层的正常波动,BBR 直接忽视这类噪声,才能稳定跑满带宽。
会不会有副作用?
有几个常被问到的点:
-
BBR 会不会对邻居不公平? 会,稍微。BBR 相比 CUBIC 更"敢抢带宽”(因为它不会因为对方的流量导致轻微丢包就退让)。在你独享 VPS、独享公网 IP 的场景下没影响;在共享物理机的极端情况下,可能让隔壁 CUBIC 用户的连接稍慢一点。
-
对局域网、零丢包场景有帮助吗? 基本没有。此时 CUBIC 也能跑满带宽,BBR 只是持平。BBR 只在丢包链路上出奇迹。
-
BBR 只影响 TCP,UDP 不受影响。 如果你走的是 WireGuard、Easytier、Hysteria2 这类 UDP 隧道,隧道本身不受 BBR 加速。但隧道内部承载的 TCP 流量(HTTP、SSH、git、rsync)会全面加速——这正是最常见的实际场景。
四、问题根因总结
把整个链条拉通梳理一下:
| 层 | 状态 | 是否是根因 |
|---|---|---|
| 物理层:国际光缆到目标机房 | 稳定丢包 6-10% | 无法治愈的客观现实 |
| 传输层 TCP:默认 CUBIC 算法 | 把每次丢包当拥塞信号 | 就是它! |
| 应用层 HTTP:Nginx / Caddy 等 | 完全正常 | 不是问题 |
| 业务层:CLIProxyAPI / Web Panel | 完全正常 | 不是问题 |
根因只有一个:Linux 默认使用 CUBIC 拥塞控制,与国际链路的丢包特性天然不匹配。
好消息是——修它只需要 3 行 shell。
五、如何解决:一键脚本(三大操作系统)
前置检查:内核版本
BBR 需要 Linux 内核 ≥ 4.9。这个门槛现在早就不是门槛:
- Ubuntu 20.04 及以上:完全支持
- Ubuntu 26.04 (LTS 计划):内核 6.8+,随时可用
- Debian 11 及以上:内核 5.10+,可用
- CentOS Stream 9:可用
- Ubuntu 18.04:内核 4.15,可用(我实测过)
- CentOS 7 原生内核 3.10:不支持,需要先升级内核
Windows 11 和 macOS 26 是客户端角色(对端是 Linux VPS),本文的重点是在 Linux 服务器侧启用 BBR。客户端本身也提供了一键脚本,用于诊断链路质量和验证服务器侧配置是否生效。
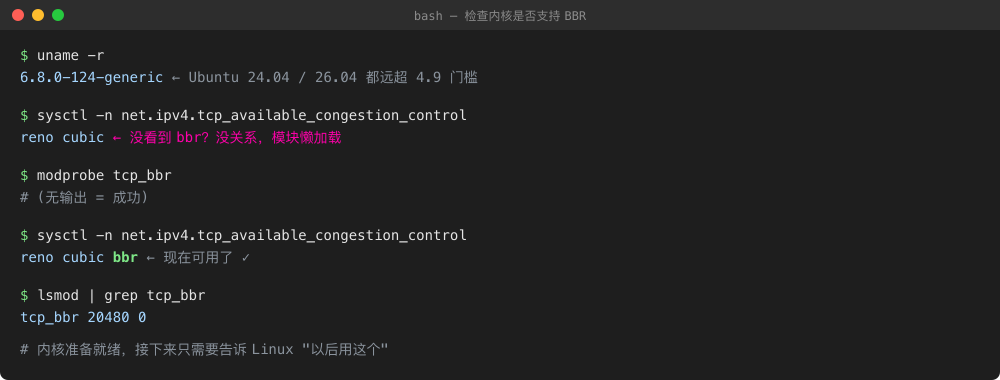
图 5:整个"预检"过程只需要 3 条命令,出问题的地方通常都会立刻暴露。
方法一:人工自动执行(Linux 服务器侧)
在 Ubuntu 26.04 / 24.04 / 22.04 / 20.04 / 18.04、Debian、任意 Linux 发行版上都通用。以 root 执行:
#!/usr/bin/env bash
# enable_bbr_ubuntu.sh — 幂等,可重复运行
set -euo pipefail
# 1. 检查内核版本
KV=$(uname -r | awk -F. '{print $1"."$2}')
MAJ=${KV%.*}; MIN=${KV##*.}
if (( MAJ < 4 || (MAJ == 4 && MIN < 9) )); then
echo "ERROR: 内核版本 $(uname -r) 太老,需要 4.9+"
echo " Ubuntu: sudo apt install --install-recommends linux-generic-hwe-\$(lsb_release -sr)"
exit 1
fi
# 2. 立刻加载 BBR 模块
modprobe tcp_bbr
# 3. 开机持久化加载
echo "tcp_bbr" > /etc/modules-load.d/bbr.conf
# 4. 写入 sysctl 持久配置(幂等:先删除旧的,再追加)
sed -i '/^net\.core\.default_qdisc/d;/^net\.ipv4\.tcp_congestion_control/d' /etc/sysctl.conf
cat >> /etc/sysctl.conf <<EOF
# --- BBR 拥塞控制(丢包链路必备) ---
net.core.default_qdisc = fq
net.ipv4.tcp_congestion_control = bbr
EOF
# 5. 立即生效
sysctl -p
# 6. 验证
echo "--- 验证结果 ---"
echo "当前算法: $(sysctl -n net.ipv4.tcp_congestion_control)"
echo "当前队列: $(sysctl -n net.core.default_qdisc)"
echo "可用算法: $(sysctl -n net.ipv4.tcp_available_congestion_control)"
lsmod | grep tcp_bbr || echo "WARN: tcp_bbr 未在 lsmod 中"
保存为 enable_bbr.sh 后 chmod +x 并以 root 运行即可。5 秒完成,全过程无害幂等——重复运行不会重复添加行。
如果对端是 Windows 11(客户端诊断脚本,PowerShell 5.1+,不改注册表,只测量):
# check-tcp-throughput.ps1 — 客户端侧带宽验证
$ErrorActionPreference = 'Stop'
$targets = @('目标域名或 IP:8317/大文件路径') # 替换为你的目标
foreach ($t in $targets) {
Write-Host "→ 测试 $t"
$stopwatch = [Diagnostics.Stopwatch]::StartNew()
try {
$r = Invoke-WebRequest -Uri "http://$t" -TimeoutSec 90 -UseBasicParsing
$stopwatch.Stop()
$sec = [math]::Round($stopwatch.Elapsed.TotalSeconds, 2)
$kb = [math]::Round($r.RawContentLength / 1024, 0)
$sp = if ($sec -gt 0) { [math]::Round($kb / $sec, 1) } else { 0 }
Write-Host (" OK: {0} KB in {1}s = {2} KB/s" -f $kb, $sec, $sp) -ForegroundColor Green
} catch {
Write-Host " 失败: $_" -ForegroundColor Red
}
}
Windows 11 客户端不需要改任何设置——它默认的 TCP 拥塞控制(CTCP)在客户端角色下表现足够好;真正的瓶颈永远在服务器侧发送 TCP 数据时。
如果对端是 macOS 26(客户端诊断脚本,用系统自带 curl):
#!/usr/bin/env bash
# check-tcp-throughput-macos.sh — 客户端带宽验证
set -euo pipefail
TARGETS=(
"目标域名或 IP:8317/大文件路径"
)
for t in "${TARGETS[@]}"; do
echo "→ 测试 $t"
curl -s -o /dev/null \
-w " HTTP: %{http_code} time: %{time_total}s speed: %{speed_download} B/s\n" \
--max-time 90 "http://$t"
done
macOS 26 本身用的是 BSD 内核,它有自己的拥塞控制(默认 cubic-like),但同样:客户端侧几乎不影响国际链路吞吐。
方法二:AI Agent 自动配置(推荐让 Agent 一次性搞定所有 VPS)
如果你手上有多台 VPS 需要一起改,交给 Claude Code / Codex / Gemini CLI 这类支持 Bash 工具的 AI Agent 是最省事的做法。下面这个 prompt 我实测过——给一个 Agent 加上你所有 VPS 的 SSH 访问权限,然后直接扔过去:
【任务】在多台远程 Linux 主机上启用 TCP BBR 拥塞控制 + fq qdisc,实测并出报告。
【要求】
1. 依次 SSH 到以下主机(我提供 SSH 别名,你不需要知道真实 IP):
host-a, host-b, host-c
2. 对每台:
- 检查内核版本,如果 < 4.9 请立刻停止并向我报告
- 幂等地开启 BBR:modprobe + /etc/modules-load.d/bbr.conf + /etc/sysctl.conf 追加两行 (default_qdisc=fq, tcp_congestion_control=bbr)
- sysctl -p 生效
- 验证 sysctl -n net.ipv4.tcp_congestion_control 输出为 bbr
3. 在改动前和改动后,都跑一遍从我本地 curl 大文件的测试(你决定用哪个 URL 作为 baseline,选一个 1 MB+ 的静态文件),记录 speed_download 数值。
4. 最后给我一个 Markdown 表格,列 hostname / before speed / after speed / 提升倍数。
【安全边界】
- 修改前先备份 /etc/sysctl.conf
- 每一步失败立即中止,不要试图"猜"或"绕过"
- 每台机器改动前请打印它当前的 kernel version 和 congestion control 让我确认
- 全程不要动 /etc/sysctl.conf 里其它已有的行
Agent 会自己规划步骤、执行、比对结果、汇总输出。整个过程你只需要给它 SSH 配置权限就行,不需要在每台机器上手动登陆。
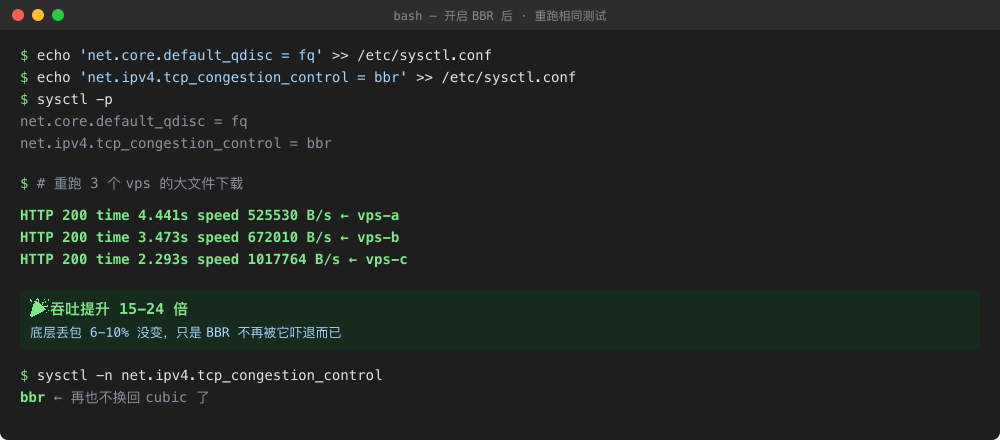
图 6:这是真的。同一台机器,同一个测试脚本,同一时刻,仅仅"改了一行 sysctl",吞吐涨了 15-24 倍。图中三个数字分别对应三台 VPS。
验证:确认配置真的生效
改完之后有三样东西必须都对上:
sysctl -n net.ipv4.tcp_congestion_control→ 输出bbrsysctl -n net.core.default_qdisc→ 输出fqlsmod | grep tcp_bbr→ 有一行(模块已加载)
任何一样对不上,说明脚本没跑全或者被别的配置文件覆盖了(比如 /etc/sysctl.d/*.conf 里有优先级更高的旧值)。
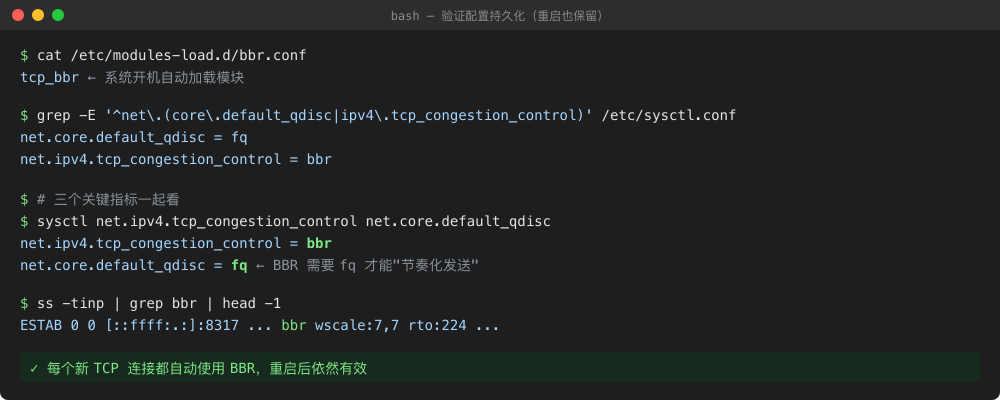
图 7:三个文件、三个 sysctl、一个 lsmod 全部对上,就是"永久生效"了。也可以用 ss -tinp | grep bbr 观察实际的 TCP 连接是不是在用 BBR。
六、Q&A
Q1. BBR 到底是 Google 在生产上用的吗?
是的。Google 从 2016 年在 YouTube 上大规模启用 BBR。根据 ACM Queue 论文披露的数据,YouTube 的平均吞吐提升了 4%,某些国家(尤其是链路质量差的地区)提升可达 14%;中位数视频延迟减少 33%。Google Cloud、YouTube 的所有服务器都默认跑 BBR。
Q2. BBR v1 / v2 / v3 有什么区别?我要不要用最新的?
- BBR v1:Linux 4.9+ 主线,就是本文启用的这个版本。缺点是在跟 CUBIC 竞争同一个瓶颈时会"抢"更多带宽,对邻居不太公平。
- BBR v2 / v3:Google 内部有更公平的实现,但没有合入 Linux mainline,只有魔改内核(比如 XanMod)才有。除非你的用途是"公开的、有很多邻居的 CDN 节点",否则用 v1 已经完全够用。
Q3. 为什么 fq qdisc 是必须的?
BBR 的核心机制之一是 pacing(节奏化发送)——它不像 CUBIC 那样把一批包"啪"一下推出去,而是均匀地分散在一个时间段里发。这就需要底层 qdisc(队列管理算法)能够按精确时间点释放包。fq(Fair Queue)就是干这个的。用 pfifo_fast(老默认值)跑 BBR 会失效很多优化。
Q4. 会不会跟 KCP、Hysteria2、WireGuard 等 UDP 方案冲突?
不会。BBR 只作用于 Linux 内核里的 TCP 栈。你的 UDP 隧道协议(Hysteria2、WireGuard、Easytier)在应用层跑自己的拥塞控制,跟 BBR 完全独立。但是——如果你的 UDP 隧道里承载了 TCP 流量(比如你 SSH、HTTP、rsync 走隧道),那么隧道两端的机器都开 BBR,隧道内的 TCP 依然会享受 BBR 的加速。这是最常见也最实用的场景。
Q5. 我改了但没效果,怎么排查?
按顺序检查:
sysctl -n net.ipv4.tcp_congestion_control是不是bbr?如果不是,说明配置没生效(可能被/etc/sysctl.d/里其他文件覆盖)。- 内核太老?
uname -r看下,4.9 以下不行。 - 你测的是不是 UDP 流量?BBR 对 UDP 完全无效。
- 底层链路是不是本来就没瓶颈?如果 CUBIC 也能跑满,BBR 只会持平不会更快。BBR 只解决"因为丢包被 CUBIC 冤枉减速"的场景。
- 客户端侧(比如你从家里的 Windows 上访问)也可能是瓶颈——但通常客户端下载数据时,是服务器侧发送,所以只需要改服务器;只有当你上传大文件到服务器时,客户端的 TCP 发送方拥塞算法才会有影响。
Q6. 除了 BBR 还有别的手段吗?比如 CDN、CloudFlare?
有,但都不如 BBR 简单:
- CloudFlare 免费版:中国大陆用户经常被解析到美国边缘节点,效果不明显;能加速的只有 HTTP 静态资源
- CloudFlare Tunnel:适合暴露公开的 HTTP 服务,但底层 TCP 依然走中国到境外的国际出口
- Hysteria2 / TUIC / v2ray+mKCP:这类 UDP + FEC 隧道在丢包更严重(15%+)的场景下比 BBR 更强,但需要额外部署和维护
- 中转 VPS(香港/日本/新加坡):物理层最优解,但要多付月费
大多数场景下,先启用 BBR,评估之后如果吞吐依然不满意(一般是丢包 > 20% 或有严重时段拥塞),再考虑 UDP 隧道加中转。
Q7. 这个改动会不会影响我 VPS 上其他服务?比如 Nginx 反代?
不会。BBR 是一个全局默认——所有新的 TCP 连接都会用它,包括 Nginx 上游连接、你的应用与数据库、rsync、apt 更新,等等。老连接维持原来的算法直到关闭。这个改动没有任何服务需要重启。你不需要重新加载 nginx,也不需要重启数据库。
七、结语
Linux 网络子系统里"改一行就有巨大收益"的地方其实不多,BBR 是其中最典型的一个。它的门槛低(脚本 3-5 行)、副作用可控(几乎没有)、收益直观(吞吐 15-24 倍)、场景明确(丢包 5-20% 的国际链路)。
如果你手上有任何跨境 Linux 服务器,无论是自用 VPS 还是给团队搭的开发环境,我建议现在就跑一遍前面的脚本,5 分钟的事,效果立竿见影。
网络优化没有银弹,但 BBR 是我这些年见过最接近银弹的一个。
参考资料
- BBR: Congestion-Based Congestion Control (ACM Queue, 2016) — Google 的原始论文
- Linux kernel BBR TCP module source — 官方内核实现
- TCP BBR congestion control comes to GCP — Google Cloud 上线公告
- YouTube performance with BBR — Google 官方 YouTube 部署实测数据
- Linux Kernel Documentation: tcp_bbr — 内核官方文档