别再让 Agent 吞掉你的 Token:我把 Headroom 接到 NewAPI、OpenClaw 和 HermesAgent 的完整实战
先说结论
这次我没有替换原来的 NewAPI,也没有让 OpenClaw / HermesAgent 直接改用一个不确定的新网关。真正做法是:在 NewAPI 前面加一层 Headroom 代理,把所有已经使用 OpenAI-compatible 协议的调用改到
http://<headroom-host>:8787/v1,而原来的 NewAPI 入口继续保留。这样 Agent 发来的长上下文先经过 Headroom 压缩,再转发给 NewAPI,最后仍由 NewAPI 统一路由到后端模型。最关键的原则只有一句:先测试,后修改;只迁移测试通过的 OpenAI-compatible 项;非 OpenAI 协议的 fallback 不碰。 这篇文章既是复盘,也是一份可以直接交给 Agent 或人工照着执行的操作指南。

封面:Agent 请求先经过 Headroom 压缩层,再进入 NewAPI。图中没有真实主机名、内网地址或密钥。
一、问题背景:Agent 很聪明,但也很会“吃 Token”
最近我把 OpenClaw 和 HermesAgent 都接到了一个统一的 NewAPI 网关上。这样做的好处很明显:模型、额度、密钥和路由都集中管理,OpenClaw / HermesAgent 只要认一个 OpenAI-compatible 入口,就能在不同模型之间切换。
但 Agent 的工作方式天然会消耗大量上下文。它会读文件、抓日志、列目录、解释错误、保留历史对话,还会把工具输出再塞回下一轮请求里。一次普通的“帮我查一下服务为什么失败”,很快就会变成几万 token。就像你让同学帮你找作业本,他不仅把作业本拿来,还把整个书包、书桌、抽屉、昨天的聊天记录都搬到你面前。
Headroom 的定位正好卡在这里。它不是新的模型供应商,也不是要替代 NewAPI 的网关,而是一个“上下文压缩层”。按照 Headroom 项目自己的介绍,它可以以 library、proxy、MCP 等方式工作,目标是把 Agent 读到的日志、工具输出、文件内容和历史上下文压缩后再送给模型。对我这套环境来说,最适合的是 proxy 模式:OpenClaw / HermesAgent 继续讲 OpenAI-compatible 协议,只是 base_url 从 NewAPI 改成 Headroom。
用生活里的比喻说,NewAPI 是仓库大门,后面连着很多快递公司;Headroom 是大门前的打包台。原来 Agent 抱着一堆蓬松棉被直接进仓库,现在先在打包台抽真空、贴标签、保留取回原件的方法,再交给仓库。仓库还是原来的仓库,快递公司还是原来的快递公司,只是包裹变小了。
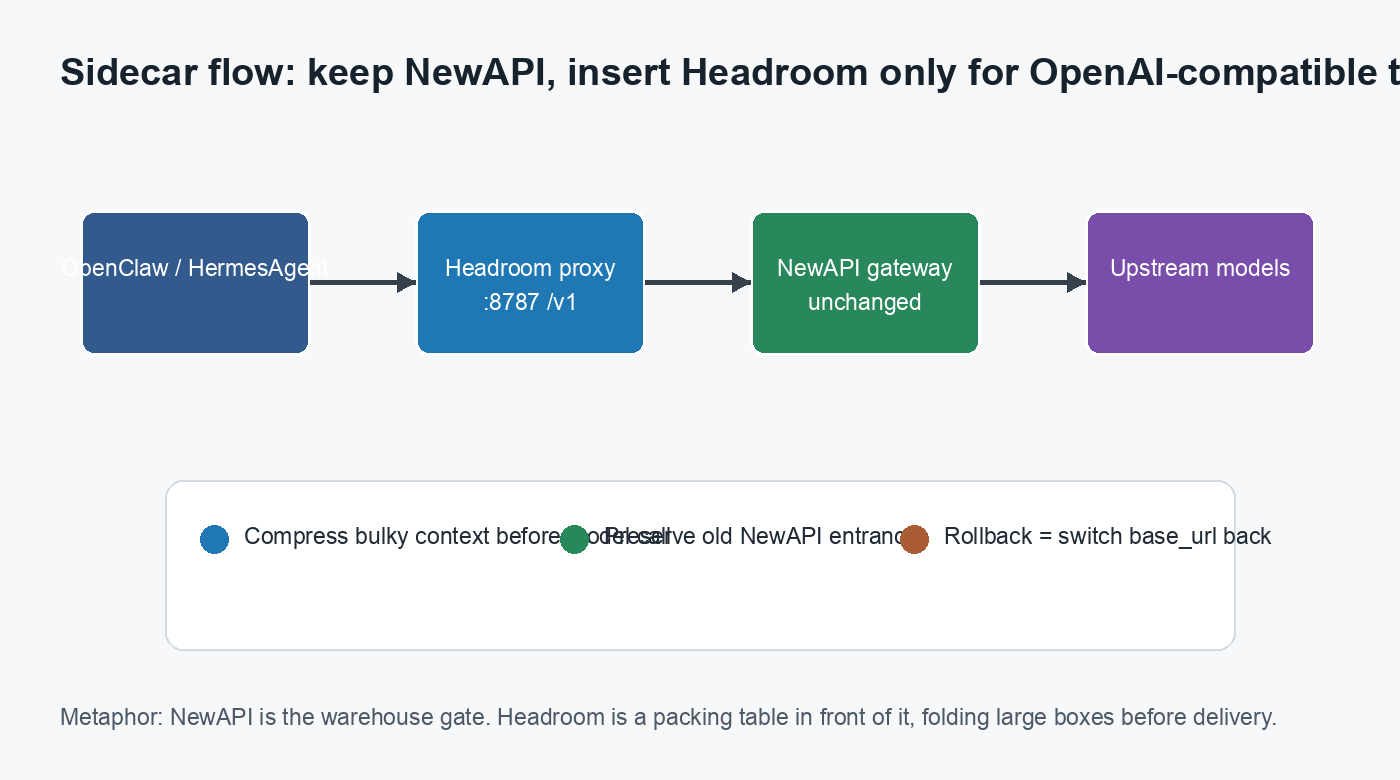
图 1:Headroom 是 sidecar,不是替代 NewAPI。旧入口继续可用,新入口只承接已经验证通过的 OpenAI-compatible 流量。
二、问题表现:不是“接上就完了”,中间有两个坑
这次真正踩到的第一个坑,是镜像在旧虚拟机位置上启动失败。容器日志里最显眼的是 Fatal Python error: Illegal instruction,退出码是 132。这不是端口写错,也不是环境变量写错,而是 CPU 指令集不匹配:镜像里的某个原生扩展在启动时调用了当前 CPU 不支持的指令。
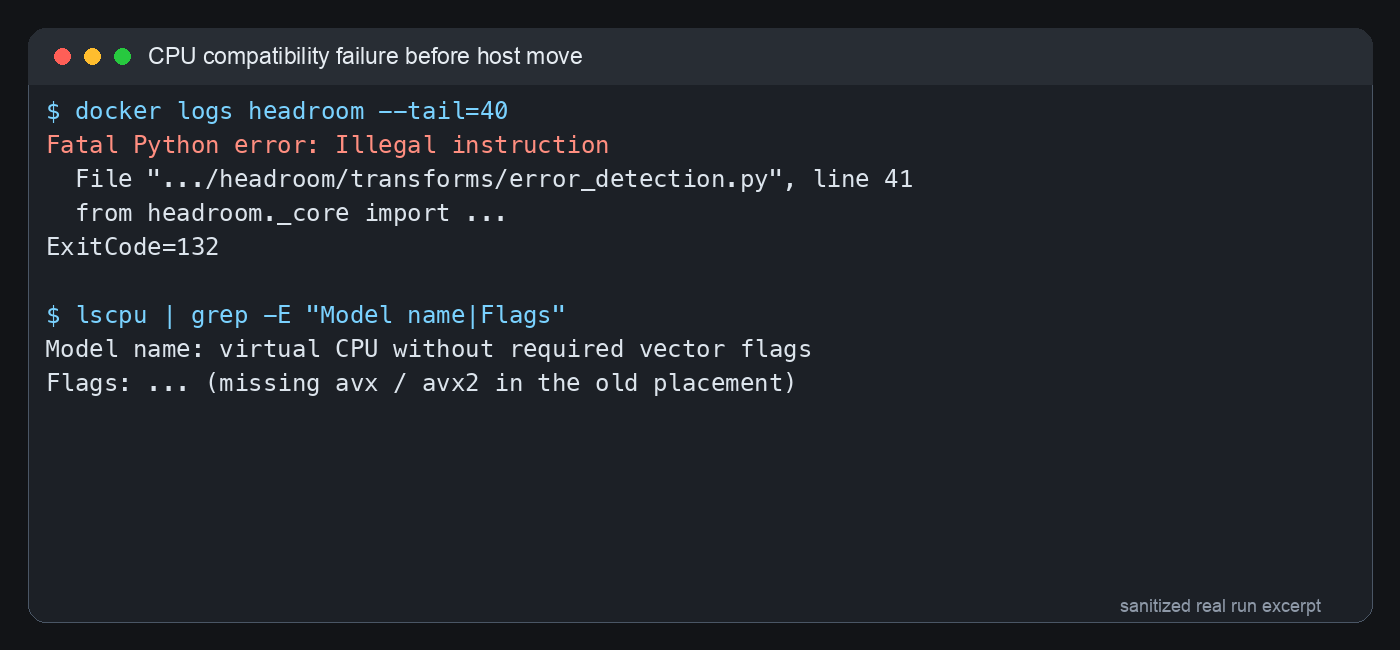
图 2:真实排错过程的脱敏终端截图。Illegal instruction 的重点不是 Python 语法错误,而是底层 CPU 指令集。
这个问题很像你买了一个需要三孔插座的电器,却拿到只有两孔插座的老房间里用。电器没有坏,房间也没有坏,但插不上。后来虚拟机切到新的宿主机,CPU 类型也调整为 host,重新检查后 headroom._core 可以正常加载,headroom-proxy --version 也能输出版本,说明镜像本身可以继续使用,不需要自己重新编译。
第二个坑更隐蔽:容器里 Headroom 实际监听的是 3000,但最初 stack 暴露和健康检查都写成了 8787。于是外面访问 8787 不通,健康检查也失败。这个问题不是服务没启动,而是“门牌号贴错了”。家里有人在 3000 号房间等你,你却一直敲 8787 号房间,当然没人开门。
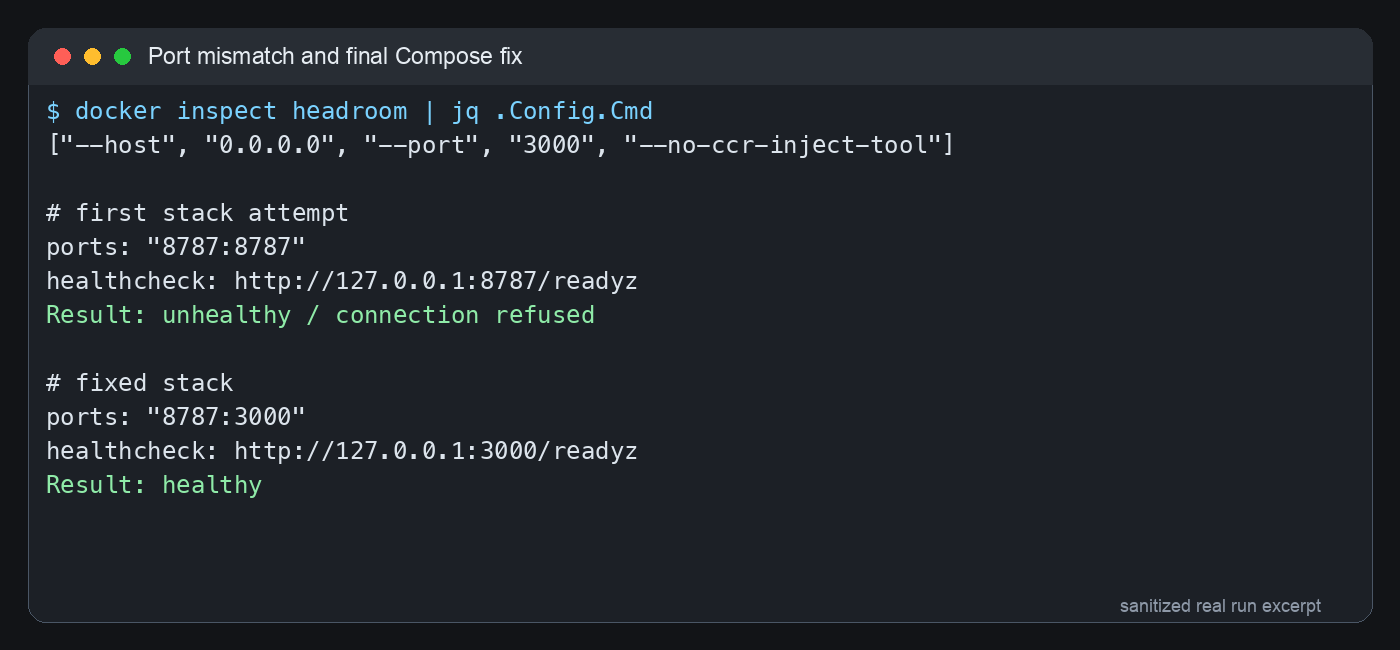
图 3:真实排错过程的脱敏终端截图。最终是宿主机 8787 映射到容器内 3000,健康检查也打容器内 3000。
修正后,Headroom 的就绪检查返回健康状态,版本显示为 0.26.0,Rust core 也已经加载。更重要的是,用假 token 请求 /v1/chat/completions、/v1/responses、/v1/completions 时,请求能穿过 Headroom 到达 NewAPI,并返回 NewAPI 的认证错误,同时响应头里带有 Headroom 标识。这证明它不是一个孤立的健康页,而是真的在代理 OpenAI-compatible 请求。
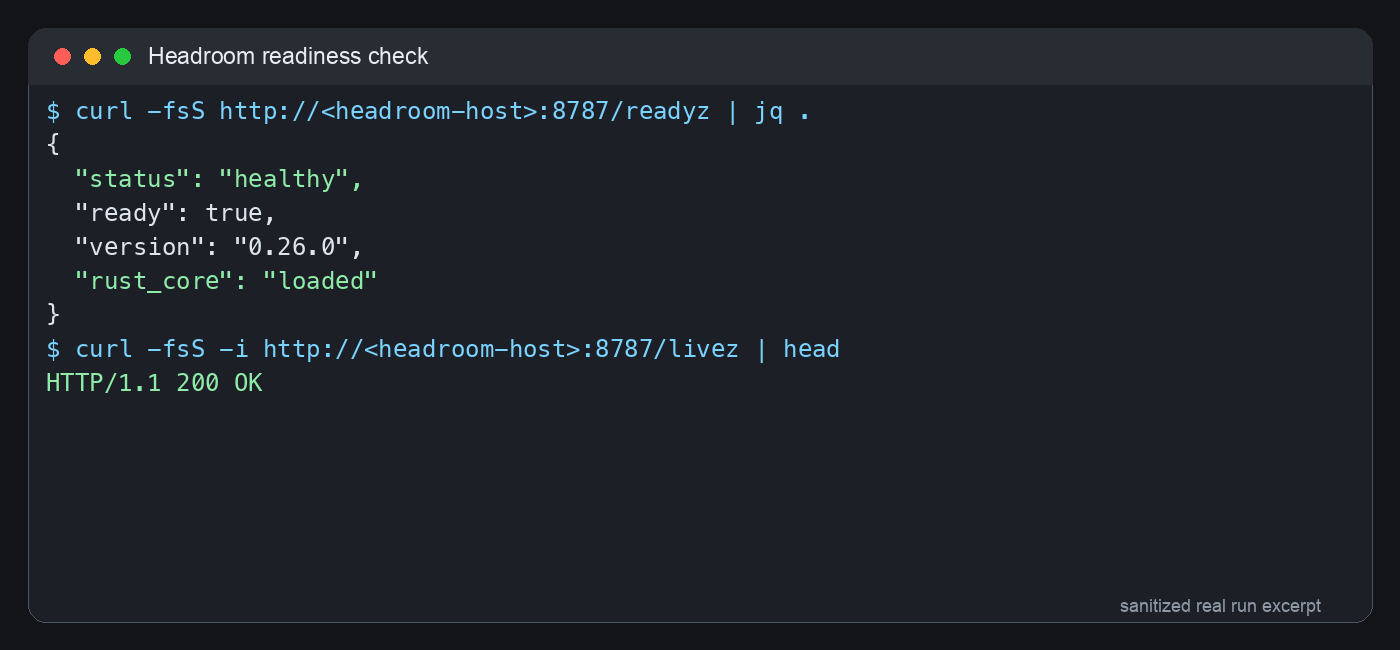
图 4:真实就绪检查的脱敏终端截图。ready=true 只能说明 Headroom 自身健康,还要继续测 OpenAI-compatible 请求是否能穿透到后端。
三、部署 Headroom:Portainer Stack 的最小可用模板
下面是脱敏后的 Portainer Stack 思路。镜像地址、网络名、NewAPI 地址都要按你的环境替换;不要把内网地址、token、真实域名写进公开仓库。
services:
headroom:
image: registry.example.local/chopratejas/headroom:latest
restart: unless-stopped
environment:
HEADROOM_TELEMETRY: "off"
OPENAI_TARGET_API_URL: http://new-api:3000
command: ["--host", "0.0.0.0", "--port", "3000", "--no-ccr-inject-tool"]
ports:
- "8787:3000"
networks:
- new-api_default
healthcheck:
test: ["CMD", "curl", "--fail", "--silent", "http://127.0.0.1:3000/readyz"]
interval: 30s
timeout: 5s
retries: 5
networks:
new-api_default:
external: true
这里有三点值得强调。
第一,OPENAI_TARGET_API_URL 指向的是 NewAPI 的内部地址,而不是公网地址。Headroom 和 NewAPI 在同一个 Docker 网络里时,直接用服务名更稳,也避免把内部入口暴露给不该访问的人。
第二,ports 是 8787:3000,不是 8787:8787。我的目标是让外部客户端访问 http://<headroom-host>:8787/v1,但容器内进程监听 3000,所以宿主机端口和容器端口可以不同。
第三,健康检查要打容器内部真实监听端口。健康检查运行在容器内部,127.0.0.1 指的是容器自己,不是宿主机。如果你让它打 127.0.0.1:8787,它会一直失败。
部署后先不要急着改客户端配置,先做三层测试:
curl -fsS http://<headroom-host>:8787/readyz
curl -fsS http://<headroom-host>:8787/livez
curl -sS http://<headroom-host>:8787/v1/chat/completions \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{"model":"<model>","messages":[{"role":"user","content":"reply OK"}],"max_tokens":8}'
readyz 和 livez 是服务体检;chat/completions 才是业务链路体检。前两个像量体温,第三个像让病人下床走两步。只量体温正常,不代表能跑步。
四、迁移策略:先测旧路,再测新路,通过才改
部署 Headroom 之后,真正风险不在 Headroom,而在客户端配置迁移。OpenClaw 和 HermesAgent 里可能有多个 provider:有些是 OpenAI-compatible,有些是 Anthropic-compatible,有些可能早就坏了。如果一刀切把所有 base_url 都改成 Headroom,就会把原来还能用的 fallback 也弄坏。
我的迁移规则是:
- 读配置,列出所有 provider 的
base_url、模型名和协议模式。 - 对每个 OpenAI-compatible provider,先用旧 NewAPI 入口发一个最小
chat/completions测试。 - 再用同一组 key 和 model,改成 Headroom 入口发同样测试。
- 只有“旧入口正常 + Headroom 入口正常”的项,才正式修改配置。
- 旧入口本来就 503、Headroom 也 502 的项,不迁移,避免把历史坏配置伪装成新问题。
- Anthropic 协议的 fallback 不迁移,除非你另行部署并验证了对应协议的兼容入口。
这套规则很像给一排水管换过滤器。你不能把全屋水管一起剪开,而是先确认每根管子原来有水,再接上新过滤器试水;原来就没水的管子先贴标签,不要混进本次验收。
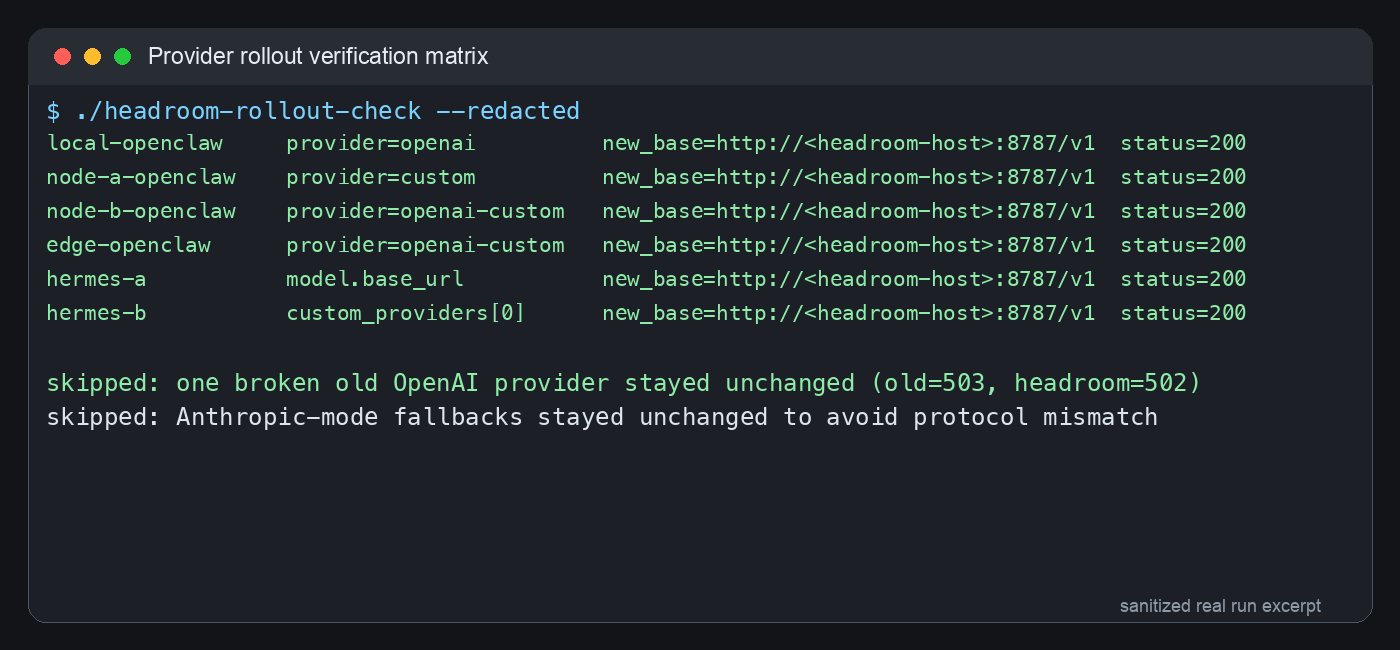
图 5:真实迁移后的脱敏验证矩阵。只迁移返回 200 的 OpenAI-compatible 项,失败项和 Anthropic-mode fallback 保持原样。
五、OpenClaw 怎么改:本地和远端都一样,路径不同
OpenClaw 的核心是 JSON 配置。本地一般在:
~/.openclaw/openclaw.json
远端 Linux 节点一般在:
/root/.openclaw/openclaw.json
正式修改前先备份:
cp ~/.openclaw/openclaw.json ~/.openclaw/openclaw.json.bak-headroom-$(date +%Y%m%d-%H%M%S)
然后只改通过测试的 provider,把原来的 NewAPI base_url 替换为:
http://<headroom-host>:8787/v1
如果你让 Agent 执行,可以直接给它下面这段任务描述:
请读取 OpenClaw 配置,找出所有 OpenAI-compatible provider。
对每个 provider 先用当前 base_url 和现有 key/model 调用 /chat/completions 做最小测试,
再把 base_url 临时替换为 http://<headroom-host>:8787/v1 做同样测试。
仅对两次都返回 200 的 provider 修改配置;修改前创建 .bak-headroom-时间戳备份;
不要修改 Anthropic 协议 provider;不要打印或保存密钥。
修改后重启 OpenClaw gateway,并再次对所有已修改 provider 做 200 验证。
人工操作时可以用 jq 查看 provider 列表,用编辑器改 JSON。改完后重启:
openclaw gateway restart
openclaw gateway status --json
远端 Linux 如果是 systemd 托管,也可以用:
systemctl restart openclaw-gateway
systemctl is-active openclaw-gateway
openclaw status --json
我这次本地 OpenClaw 和多台远端 OpenClaw 节点都按这个办法迁移。一个旧 provider 本来就返回 503,经过 Headroom 也只能变成 502,所以保持不动。这个细节很重要:迁移不是修复所有历史配置,迁移只是把健康链路接入压缩层。
六、HermesAgent 怎么改:注意 api_mode
HermesAgent 的配置通常是 YAML,例如:
/root/.hermes/config.yaml
这次需要看的字段主要有三类:
model:
provider: custom
default: <model>
base_url: http://<headroom-host>:8787/v1
api_mode: chat_completions
providers:
openai-custom:
base_url: http://<headroom-host>:8787/v1
custom_providers:
- name: newapi-through-headroom
base_url: http://<headroom-host>:8787/v1
api_mode: chat_completions
注意 api_mode。如果某个 fallback 明确是 anthropic 或者指向 Anthropic 原生接口,就不要把它强行改到本次 Headroom 入口。协议不一样,强改相当于让说中文的人去参加英文听力考试,失败不是模型笨,而是题目给错了语言。
修改前同样先备份:
cp /root/.hermes/config.yaml /root/.hermes/config.yaml.bak-headroom-$(date +%Y%m%d-%H%M%S)
修改后重启 Hermes gateway:
systemctl restart hermes-gateway
systemctl is-active hermes-gateway
hermes fallback list
如果某台机器使用 user service,则改成:
systemctl --user restart hermes-gateway
systemctl --user is-active hermes-gateway
我这次只迁移了 chat_completions / OpenAI-compatible 的主模型、custom provider 和可验证 fallback;明确属于 Anthropic 协议的 fallback 保持原样。这样做的好处是:Headroom 只接它擅长接的流量,原有兜底链路不会因为一次迁移被误伤。

图 6:同一件事可以交给 Agent,也可以人工执行。核心都是“测试先于修改”。
七、回滚方案:把 base_url 改回去就行
这种 sidecar 接入方式的最大好处,是回滚非常简单。因为 NewAPI 没变,密钥没变,模型没变,客户端只是从:
http://<newapi-host>:3000/v1
切到了:
http://<headroom-host>:8787/v1
如果某个客户端出现问题,直接恢复备份或把 base_url 改回旧入口即可。不要删除旧入口,不要急着清理 NewAPI,也不要在同一次变更里顺手改模型。一次只改一个变量,排错才不会像在黑屋子里找黑猫。
我建议在每台机器上保留两个东西:
*.bak-headroom-时间戳配置备份;- 一份脱敏的迁移记录:哪些 provider 改了、哪些 provider 跳过、跳过原因是什么。
这份记录以后非常有用。三个月后你看到某个 provider 还没走 Headroom,不需要猜“当时是不是忘了”,看记录就知道它是旧入口 503,所以故意没改。
八、Q&A
Q1:为什么不直接替换 NewAPI?
因为 NewAPI 负责统一模型、密钥、额度和路由,已经是稳定入口。Headroom 解决的是上下文压缩问题,不应该顺手接管所有网关职责。把 Headroom 放在 NewAPI 前面,就像在仓库门口加打包台,而不是重建仓库。
Q2:Headroom 会压缩所有请求吗?
它能处理经过它的 OpenAI-compatible 请求,但实际压缩收益取决于请求内容。长日志、工具输出、RAG 片段、文件内容更容易获得明显收益;一句“你好”没有多少可压缩空间。
Q3:为什么 Anthropic fallback 不一起改?
这次部署验证的是 OpenAI-compatible 入口。Anthropic 原生协议和 OpenAI-compatible 协议请求结构不同。没有单独验证之前,不要把 Anthropic fallback 强行塞进 OpenAI-compatible 代理。
Q4:Illegal instruction 怎么办?
先看 CPU 指令集和容器日志。如果镜像里包含原生扩展,而当前虚拟 CPU 没暴露必要指令,就会出现退出码 132。解决方向有三个:换支持指令集的宿主机、把虚拟机 CPU 类型改成 host、或者使用与旧 CPU 兼容的镜像。我的做法是继续使用现成镜像,但把 VM 放到支持指令集的宿主机上。
Q5:容器显示 unhealthy,但进程又像启动了,怎么查?
先看进程实际监听端口,再看 Compose 的端口映射和 healthcheck。容器内监听 3000,healthcheck 却打 8787,就会假失败。健康检查要站在“容器内部视角”理解。
Q6:如何避免泄露密钥?
测试命令里不要 echo $API_KEY,日志截图前先脱敏,文章和 Git 仓库里只写 $API_KEY、<headroom-host>、registry.example.local 这类占位符。配置备份留在服务器本地,不要提交到仓库。
九、给 Agent 的一句话操作指南
如果你已经有 NewAPI、OpenClaw 和 HermesAgent,可以把下面这段直接交给 Agent:
请部署 Headroom 作为 NewAPI 前置 OpenAI-compatible proxy。
要求:使用现成 headroom 镜像;以 Portainer/Docker Compose 部署;外部暴露 http://<headroom-host>:8787/v1;
容器内如果监听 3000,则端口映射必须是 8787:3000,healthcheck 也检查容器内 3000。
部署后先验证 /readyz、/livez、/v1/chat/completions、/v1/responses 和 /v1/completions。
然后读取本地和远端 OpenClaw/HermesAgent 配置,逐个 provider 先测旧 NewAPI 入口,再测 Headroom 入口。
只修改两边都返回 200 的 OpenAI-compatible provider;保留 Anthropic-mode fallback;修改前备份;修改后重启服务并复测。
全程不要输出密钥,不要把内网地址写进公开文件。
人工执行时,把这句话拆成四张清单即可:部署清单、Headroom 健康检查清单、provider 测试清单、客户端改配置清单。顺序不要乱。
十、总结
这次接入 Headroom 的关键不是“把一个新工具跑起来”,而是把它放在合适的位置:NewAPI 前面、OpenAI-compatible 流量中间、客户端配置可回滚的那一层。
最终形态很清楚:NewAPI 继续做统一网关,Headroom 做上下文压缩,OpenClaw / HermesAgent 只把已经验证过的 OpenAI-compatible provider 改到 Headroom。旧入口保留,Anthropic fallback 保留,失败 provider 保留现场。这样既能引入 token 压缩,又不会把原本稳定的系统改成一个更大的未知数。
如果你也有一套自托管 Agent 环境,我建议先从一个测试 provider 开始。不要一上来全量切换。把它当成给家里的水管加过滤器:先关一小段阀门,接上,试水,不漏,再换下一段。这样做慢一点,但晚上能睡得更稳。
参考资料
- Headroom GitHub:https://github.com/chopratejas/headroom
- Headroom 文档:https://headroom-docs.vercel.app/docs
- Headroom Proxy 说明:https://headroom-docs.vercel.app/docs/proxy
- OpenClaw Gateway 文档:https://docs.openclaw.ai/cli/gateway
- HermesAgent fallback providers 文档:https://hermes-agent.nousresearch.com/docs/user-guide/features/fallback-providers